SAYF(cCYA "afl-cc " cBRI VERSION cRST " by <lcamtuf@google.com>\n"); } else be_quiet = 1;
if (argc < 2) {
SAYF("\n" "This is a helper application for afl-fuzz. It serves as a drop-in replacement\n" "for gcc or clang, letting you recompile third-party code with the required\n" "runtime instrumentation. A common use pattern would be one of the following:\n\n"
"You can specify custom next-stage toolchain via AFL_CC, AFL_CXX, and AFL_AS.\n" "Setting AFL_HARDEN enables hardening optimizations in the compiled code.\n\n", BIN_PATH, BIN_PATH);
s32 pid; u32 rand_seed; int status; u8* inst_ratio_str = getenv("AFL_INST_RATIO");
structtimevaltv; structtimezonetz;
clang_mode = !!getenv(CLANG_ENV_VAR);
if (isatty(2) && !getenv("AFL_QUIET")) {
SAYF(cCYA "afl-as " cBRI VERSION cRST " by <lcamtuf@google.com>\n"); } else be_quiet = 1;
if (argc < 2) {
SAYF("\n" "This is a helper application for afl-fuzz. It is a wrapper around GNU 'as',\n" "executed by the toolchain whenever using afl-gcc or afl-clang. You probably\n" "don't want to run this program directly.\n\n"
"Rarely, when dealing with extremely complex projects, it may be advisable to\n" "set AFL_INST_RATIO to a value less than 100 in order to reduce the odds of\n" "instrumenting every discovered branch.\n\n");
if (sscanf(inst_ratio_str, "%u", &inst_ratio) != 1 || inst_ratio > 100) FATAL("Bad value of AFL_INST_RATIO (must be between 0 and 100)");
}
if (getenv(AS_LOOP_ENV_VAR)) FATAL("Endless loop when calling 'as' (remove '.' from your PATH)");
setenv(AS_LOOP_ENV_VAR, "1", 1);
/* When compiling with ASAN, we don't have a particularly elegant way to skip ASAN-specific branches. But we can probabilistically compensate for that... */
/* All right, this is where the actual fun begins. For one, we only want to instrument the .text section. So, let's keep track of that in processed files - and let's set instr_ok accordingly. */
if (line[0] == '\t' && line[1] == '.') {
/* OpenBSD puts jump tables directly inline with the code, which is a bit annoying. They use a specific format of p2align directives around them, so we use that as a signal. */
/* An optimization is possible here by adding the code only if the label is mentioned in the code in contexts other than call / jmp. That said, this complicates the code by requiring two-pass processing (messy with stdin), and results in a speed gain typically under 10%, because compilers are generally pretty good about not generating spurious intra-function jumps. We use deferred output chiefly to avoid disrupting .Lfunc_begin0-style exception handling calculations (a problem on MacOS X). */
if (!skip_next_label) instrument_next = 1; else skip_next_label = 0;
}
} else {
/* Function label (always instrumented, deferred mode). */
instrument_next = 1; }
}
}
最后,如果进行了插桩,再插入main_payload
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
if (ins_lines) fputs(use_64bit ? main_payload_64 : main_payload_32, outf);
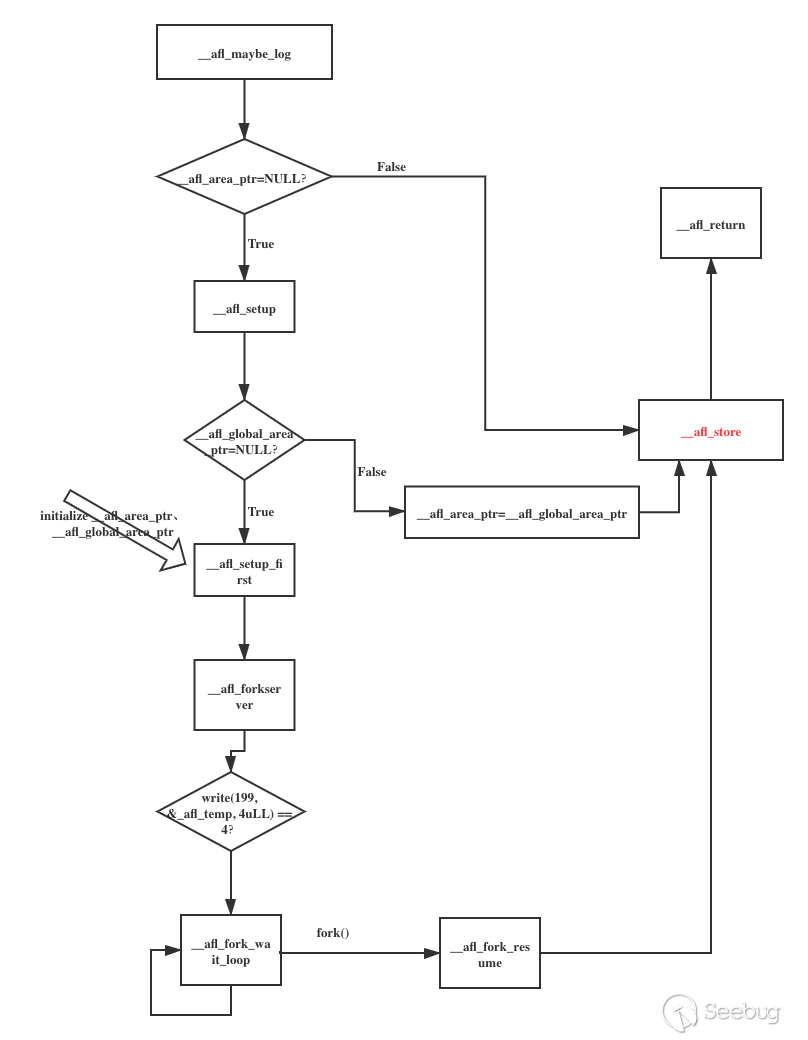
"__afl_forkserver:\n" "\n" " /* Enter the fork server mode to avoid the overhead of execve() calls. We\n" " push rdx (area ptr) twice to keep stack alignment neat. */\n" "\n" " pushq %rdx\n" " pushq %rdx\n" "\n" " /* Phone home and tell the parent that we're OK. (Note that signals with\n" " no SA_RESTART will mess it up). If this fails, assume that the fd is\n" " closed because we were execve()d from an instrumented binary, or because\n" " the parent doesn't want to use the fork server. */\n" "\n" " movq $4, %rdx /* length */\n" " leaq __afl_temp(%rip), %rsi /* data */\n" " movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */\n" CALL_L64("write") "\n" " cmpq $4, %rax\n" " jne __afl_fork_resume\n" "\n"
if (!strcmp(in_dir, out_dir)) FATAL("Input and output directories can't be the same");
if (dumb_mode) {
if (crash_mode) FATAL("-C and -n are mutually exclusive"); if (qemu_mode) FATAL("-Q and -n are mutually exclusive");
}
if (getenv("AFL_NO_FORKSRV")) no_forkserver = 1; if (getenv("AFL_NO_CPU_RED")) no_cpu_meter_red = 1; if (getenv("AFL_NO_ARITH")) no_arith = 1; if (getenv("AFL_SHUFFLE_QUEUE")) shuffle_queue = 1; if (getenv("AFL_FAST_CAL")) fast_cal = 1;
if (getenv("AFL_HANG_TMOUT")) { hang_tmout = atoi(getenv("AFL_HANG_TMOUT")); if (!hang_tmout) FATAL("Invalid value of AFL_HANG_TMOUT"); }
if (dumb_mode == 2 && no_forkserver) FATAL("AFL_DUMB_FORKSRV and AFL_NO_FORKSRV are mutually exclusive");
if (getenv("AFL_PRELOAD")) { setenv("LD_PRELOAD", getenv("AFL_PRELOAD"), 1); setenv("DYLD_INSERT_LIBRARIES", getenv("AFL_PRELOAD"), 1); }
if (getenv("AFL_LD_PRELOAD")) FATAL("Use AFL_PRELOAD instead of AFL_LD_PRELOAD");
/* If somebody is asking us to fuzz instrumented binaries in dumb mode, we don't want them to detect instrumentation, since we won't be sending fork server commands. This should be replaced with better auto-detection later on, perhaps? */
if (st.st_size > MAX_FILE) FATAL("Test case '%s' is too big (%s, limit is %s)", fn, DMS(st.st_size), DMS(MAX_FILE)); // 如果testcase太大 /* Check for metadata that indicates that deterministic fuzzing is complete for this entry. We don't want to repeat deterministic fuzzing when resuming aborted scans, because it would be pointless and probably very time-consuming. */ // 通过是否存在deterministic_done文件,来判断是否是resuming // 如果是resume,则跳过deterministic fuzz 阶段 if (!access(dfn, F_OK)) passed_det = 1; ck_free(dfn); // 将testcase添加进queue add_to_queue(fn, st.st_size, passed_det); }
最后是收尾的一些处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
free(nl); /* not tracked */
if (!queued_paths) {
SAYF("\n" cLRD "[-] " cRST "Looks like there are no valid test cases in the input directory! The fuzzer\n" " needs one or more test case to start with - ideally, a small file under\n" " 1 kB or so. The cases must be stored as regular files directly in the\n" " input directory.\n");
ACTF("Attempting dry run with '%s'...", fn); fd = open(q->fname, O_RDONLY); if (fd < 0) PFATAL("Unable to open '%s'", q->fname); use_mem = ck_alloc_nozero(q->len);
if (read(fd, use_mem, q->len) != q->len) FATAL("Short read from '%s'", q->fname);
close(fd);
然后通过 calibrate_case 对testcase进行了处理并尝试运行
1 2
res = calibrate_case(argv, q, use_mem, 0, 1); ck_free(use_mem);
if (res == crash_mode || res == FAULT_NOBITS) SAYF(cGRA " len = %u, map size = %u, exec speed = %llu us\n" cRST, q->len, q->bitmap_size, q->exec_us);
switch (res) {
case FAULT_NONE: // 如果没有错误,并且是queue的第一个testcase if (q == queue) check_map_coverage();
if (crash_mode) FATAL("Test case '%s' does *NOT* crash", fn); break;
case FAULT_TMOUT:
if (timeout_given) {
/* The -t nn+ syntax in the command line sets timeout_given to '2' and instructs afl-fuzz to tolerate but skip queue entries that time out. */
if (timeout_given > 1) { WARNF("Test case results in a timeout (skipping)"); q->cal_failed = CAL_CHANCES; cal_failures++; break; }
SAYF("\n" cLRD "[-] " cRST "The program took more than %u ms to process one of the initial test cases.\n" " Usually, the right thing to do is to relax the -t option - or to delete it\n" " altogether and allow the fuzzer to auto-calibrate. That said, if you know\n" " what you are doing and want to simply skip the unruly test cases, append\n" " '+' at the end of the value passed to -t ('-t %u+').\n", exec_tmout, exec_tmout);
FATAL("Test case '%s' results in a timeout", fn); } else {
SAYF("\n" cLRD "[-] " cRST "The program took more than %u ms to process one of the initial test cases.\n" " This is bad news; raising the limit with the -t option is possible, but\n" " will probably make the fuzzing process extremely slow.\n\n"
" If this test case is just a fluke, the other option is to just avoid it\n" " altogether, and find one that is less of a CPU hog.\n", exec_tmout);
FATAL("Test case '%s' results in a timeout", fn); }
case FAULT_CRASH:
if (crash_mode) break;
if (skip_crashes) { WARNF("Test case results in a crash (skipping)"); q->cal_failed = CAL_CHANCES; cal_failures++; break; }
if (mem_limit) {
SAYF("\n" cLRD "[-] " cRST "Oops, the program crashed with one of the test cases provided. There are\n" " several possible explanations:\n\n"
" - The test case causes known crashes under normal working conditions. If\n" " so, please remove it. The fuzzer should be seeded with interesting\n" " inputs - but not ones that cause an outright crash.\n\n"
" - The current memory limit (%s) is too low for this program, causing\n" " it to die due to OOM when parsing valid files. To fix this, try\n" " bumping it up with the -m setting in the command line. If in doubt,\n" " try something along the lines of:\n\n"
" Tip: you can use http://jwilk.net/software/recidivm to quickly\n" " estimate the required amount of virtual memory for the binary. Also,\n" " if you are using ASAN, see %s/notes_for_asan.txt.\n\n"
#ifdef __APPLE__
" - On MacOS X, the semantics of fork() syscalls are non-standard and may\n" " break afl-fuzz performance optimizations when running platform-specific\n" " binaries. To fix this, set AFL_NO_FORKSRV=1 in the environment.\n\n"
#endif/* __APPLE__ */
" - Least likely, there is a horrible bug in the fuzzer. If other options\n" " fail, poke <lcamtuf@coredump.cx> for troubleshooting tips.\n", DMS(mem_limit << 20), mem_limit - 1, doc_path); } else {
SAYF("\n" cLRD "[-] " cRST "Oops, the program crashed with one of the test cases provided. There are\n" " several possible explanations:\n\n"
" - The test case causes known crashes under normal working conditions. If\n" " so, please remove it. The fuzzer should be seeded with interesting\n" " inputs - but not ones that cause an outright crash.\n\n"
#ifdef __APPLE__
" - On MacOS X, the semantics of fork() syscalls are non-standard and may\n" " break afl-fuzz performance optimizations when running platform-specific\n" " binaries. To fix this, set AFL_NO_FORKSRV=1 in the environment.\n\n"
#endif/* __APPLE__ */
" - Least likely, there is a horrible bug in the fuzzer. If other options\n" " fail, poke <lcamtuf@coredump.cx> for troubleshooting tips.\n"); }
FATAL("Test case '%s' results in a crash", fn);
case FAULT_ERROR:
FATAL("Unable to execute target application ('%s')", argv[0]);
case FAULT_NOINST:
FATAL("No instrumentation detected");
case FAULT_NOBITS:
useless_at_start++;
if (!in_bitmap && !shuffle_queue) WARNF("No new instrumentation output, test case may be useless.");
break; }
结束了循环
最后进行了错误处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
if (cal_failures) {
if (cal_failures == queued_paths) FATAL("All test cases time out%s, giving up!", skip_crashes ? " or crash" : "");
WARNF("Skipped %u test cases (%0.02f%%) due to timeouts%s.", cal_failures, ((double)cal_failures) * 100 / queued_paths, skip_crashes ? " or crashes" : "");
if (cal_failures * 5 > queued_paths) WARNF(cLRD "High percentage of rejected test cases, check settings!"); }
if (!first_run && !(stage_cur % stats_update_freq)) show_stats(); // 如果不是第一次运行 并且state_cur 隔 stats_update_freq 次 // 则show_stats write_to_testcase(use_mem, q->len); // 将testcase写入out_file fault = run_target(argv, use_tmout); // 运行目标程序 /* stop_soon is set by the handler for Ctrl+C. When it's pressed, we want to bail out quickly. */
/* If we have a four-byte "hello" message from the server, we're all set. Otherwise, try to figure out what went wrong. */
if (rlen == 4) { OKF("All right - fork server is up."); return; }
if (child_timed_out) FATAL("Timeout while initializing fork server (adjusting -t may help)");
if (waitpid(forksrv_pid, &status, 0) <= 0) PFATAL("waitpid() failed");
if (WIFSIGNALED(status)) {
if (mem_limit && mem_limit < 500 && uses_asan) {
SAYF("\n" cLRD "[-] " cRST "Whoops, the target binary crashed suddenly, before receiving any input\n" " from the fuzzer! Since it seems to be built with ASAN and you have a\n" " restrictive memory limit configured, this is expected; please read\n" " %s/notes_for_asan.txt for help.\n", doc_path); } elseif (!mem_limit) {
SAYF("\n" cLRD "[-] " cRST "Whoops, the target binary crashed suddenly, before receiving any input\n" " from the fuzzer! There are several probable explanations:\n\n"
" - The binary is just buggy and explodes entirely on its own. If so, you\n" " need to fix the underlying problem or find a better replacement.\n\n"
#ifdef __APPLE__
" - On MacOS X, the semantics of fork() syscalls are non-standard and may\n" " break afl-fuzz performance optimizations when running platform-specific\n" " targets. To fix this, set AFL_NO_FORKSRV=1 in the environment.\n\n"
#endif/* __APPLE__ */
" - Less likely, there is a horrible bug in the fuzzer. If other options\n" " fail, poke <lcamtuf@coredump.cx> for troubleshooting tips.\n"); } else {
SAYF("\n" cLRD "[-] " cRST "Whoops, the target binary crashed suddenly, before receiving any input\n" " from the fuzzer! There are several probable explanations:\n\n"
" - The current memory limit (%s) is too restrictive, causing the\n" " target to hit an OOM condition in the dynamic linker. Try bumping up\n" " the limit with the -m setting in the command line. A simple way confirm\n" " this diagnosis would be:\n\n"
" Tip: you can use http://jwilk.net/software/recidivm to quickly\n" " estimate the required amount of virtual memory for the binary.\n\n"
" - The binary is just buggy and explodes entirely on its own. If so, you\n" " need to fix the underlying problem or find a better replacement.\n\n"
#ifdef __APPLE__
" - On MacOS X, the semantics of fork() syscalls are non-standard and may\n" " break afl-fuzz performance optimizations when running platform-specific\n" " targets. To fix this, set AFL_NO_FORKSRV=1 in the environment.\n\n"
#endif/* __APPLE__ */
" - Less likely, there is a horrible bug in the fuzzer. If other options\n" " fail, poke <lcamtuf@coredump.cx> for troubleshooting tips.\n", DMS(mem_limit << 20), mem_limit - 1); }
FATAL("Fork server crashed with signal %d", WTERMSIG(status)); }
if (*(u32 *)trace_bits == EXEC_FAIL_SIG) FATAL("Unable to execute target application ('%s')", argv[0]);
if (mem_limit && mem_limit < 500 && uses_asan) {
SAYF("\n" cLRD "[-] " cRST "Hmm, looks like the target binary terminated before we could complete a\n" " handshake with the injected code. Since it seems to be built with ASAN and\n" " you have a restrictive memory limit configured, this is expected; please\n" " read %s/notes_for_asan.txt for help.\n", doc_path); } elseif (!mem_limit) {
SAYF("\n" cLRD "[-] " cRST "Hmm, looks like the target binary terminated before we could complete a\n" " handshake with the injected code. Perhaps there is a horrible bug in the\n" " fuzzer. Poke <lcamtuf@coredump.cx> for troubleshooting tips.\n"); } else {
SAYF("\n" cLRD "[-] " cRST "Hmm, looks like the target binary terminated before we could complete a\n" " handshake with the injected code. There are %s probable explanations:\n\n"
"%s" " - The current memory limit (%s) is too restrictive, causing an OOM\n" " fault in the dynamic linker. This can be fixed with the -m option. A\n" " simple way to confirm the diagnosis may be:\n\n"
" Tip: you can use http://jwilk.net/software/recidivm to quickly\n" " estimate the required amount of virtual memory for the binary.\n\n"
" - Less likely, there is a horrible bug in the fuzzer. If other options\n" " fail, poke <lcamtuf@coredump.cx> for troubleshooting tips.\n", getenv(DEFER_ENV_VAR) ? "three" : "two", getenv(DEFER_ENV_VAR) ? " - You are using deferred forkserver, but __AFL_INIT() is never\n" " reached before the program terminates.\n\n" : "", DMS(mem_limit << 20), mem_limit - 1); }
/* In non-dumb mode, we have the fork server up and running, so simply tell it to have at it, and then read back PID. */
if ((res = write(fsrv_ctl_fd, &prev_timed_out, 4)) != 4) { // 向forkserver发送消息 if (stop_soon) return0; RPFATAL(res, "Unable to request new process from fork server (OOM?)"); }
if ((res = read(fsrv_st_fd, &child_pid, 4)) != 4) { // 接受子进程pid if (stop_soon) return0; RPFATAL(res, "Unable to request new process from fork server (OOM?)"); }
if (child_pid <= 0) FATAL("Fork server is misbehaving (OOM?)"); }
total_execs++; // 总运行次数加一 /* Any subsequent operations on trace_bits must not be moved by the compiler below this point. Past this location, trace_bits[] behave very normally and do not have to be treated as volatile. */
/* It makes sense to account for the slowest units only if the testcase was run under the user defined timeout. */ if (!(timeout > exec_tmout) && (slowest_exec_ms < exec_ms)) { slowest_exec_ms = exec_ms; } // 如果顺利运行到最后,说明没有错误 return FAULT_NONE; }
/* For every byte set in trace_bits[], see if there is a previous winner, and how it compares to us. */
for (i = 0; i < MAP_SIZE; i++)
if (trace_bits[i]) {
if (top_rated[i]) {
/* Faster-executing or smaller test cases are favored. */ // favored score由执行时间和长度相乘得到。越小越好 if (fav_factor > top_rated[i]->exec_us * top_rated[i]->len) continue;
/* Looks like we're going to win. Decrease ref count for the previous winner, discard its trace_bits[] if necessary. */
if (!--top_rated[i]->tc_ref) { ck_free(top_rated[i]->trace_mini); top_rated[i]->trace_mini = 0; } }
for (i = 0; i < MAP_SIZE; i++) if (top_rated[i] && (temp_v[i >> 3] & (1 << (i & 7)))) { // 判断favored种子遍历的区域,是否已经在之前筛选出了(将对应的temp_v置为0了) u32 j = MAP_SIZE >> 3;
/* Remove all bits belonging to the current entry from temp_v. */ // 然后将所有当前种子遍历过的区域从temp_v中去除 while (j--) if (top_rated[i]->trace_mini[j]) temp_v[j] &= ~top_rated[i]->trace_mini[j];
/* Otherwise, still possibly skip non-favored cases, albeit less often. The odds of skipping stuff are higher for already-fuzzed inputs and lower for never-fuzzed entries. */
if (orig_in == MAP_FAILED) PFATAL("Unable to mmap '%s'", queue_cur->fname);
close(fd);
/* We could mmap() out_buf as MAP_PRIVATE, but we end up clobbering every single byte anyway, so it wouldn't give us any performance or memory usage benefits. */
/* Reset exec_cksum to tell calibrate_case to re-execute the testcase avoiding the usage of an invalid trace_bits. For more info: https://github.com/AFLplusplus/AFLplusplus/pull/425 */
queue_cur->exec_cksum = 0;
res = calibrate_case(argv, queue_cur, in_buf, queue_cycle - 1, 0);
if (res == FAULT_ERROR) FATAL("Unable to execute target application"); }
if (stop_soon || res != crash_mode) { cur_skipped_paths++; goto abandon_entry; } }
/* If at end of file and we are still collecting a string, grab the final character and force output. */
if (a_len < MAX_AUTO_EXTRA) a_collect[a_len] = out_buf[stage_cur >> 3]; a_len++;
if (a_len >= MIN_AUTO_EXTRA && a_len <= MAX_AUTO_EXTRA) maybe_add_auto(a_collect, a_len); } elseif (cksum != prev_cksum) { // 如果cksum不等于prev_cksum,可能是一个魔数的开始或者结束 /* Otherwise, if the checksum has changed, see if we have something worthwhile queued up, and collect that if the answer is yes. */
for (stage_cur = 0; stage_cur < stage_max; stage_cur++) {
stage_cur_byte = stage_cur;
out_buf[stage_cur] ^= 0xFF; // 每次翻转一个byte if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry; // 运行测试 /* We also use this stage to pull off a simple trick: we identify bytes that seem to have no effect on the current execution path even when fully flipped - and we skip them during more expensive deterministic stages, such as arithmetics or known ints. */
if (!eff_map[EFF_APOS(stage_cur)]) {
u32 cksum;
/* If in dumb mode or if the file is very short, just flag everything without wasting time on checksums. */
if (!dumb_mode && len >= EFF_MIN_LEN) cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST); else cksum = ~queue_cur->exec_cksum;
for (j = 1; j <= ARITH_MAX; j++) { // 这里的 ARITH_MAX 是35 u8 r = orig ^ (orig + j); /* Do arithmetic operations only if the result couldn't be a product of a bitflip. */ // 并且要确保进行算术运算后的值不可以经过bitflip得到,避免重复变异 if (!could_be_bitflip(r)) {
stage_cur_val = j; out_buf[i] = orig + j;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry; stage_cur++;
} else stage_max--;
r = orig ^ (orig - j);
if (!could_be_bitflip(r)) {
stage_cur_val = -j; out_buf[i] = orig - j;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry; stage_cur++;
/* Extras are sorted by size, from smallest to largest. This means that we don't have to worry about restoring the buffer in between writes at a particular offset determined by the outer loop. */
for (j = 0; j < extras_cnt; j++) {
/* Skip extras probabilistically if extras_cnt > MAX_DET_EXTRAS. Also skip them if there's no room to insert the payload, if the token is redundant, or if its entire span has no bytes set in the effector map. */
if ((extras_cnt > MAX_DET_EXTRAS && UR(extras_cnt) >= MAX_DET_EXTRAS) || extras[j].len > len - i || !memcmp(extras[j].data, out_buf + i, extras[j].len) || !memchr(eff_map + EFF_APOS(i), 1, EFF_SPAN_ALEN(i, extras[j].len))) {
stage_max--; continue;
}
last_len = extras[j].len; memcpy(out_buf + i, extras[j].data, last_len);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
}
/* Restore all the clobbered memory. */ memcpy(out_buf + i, in_buf + i, last_len);
for (j = 0; j < MIN(a_extras_cnt, USE_AUTO_EXTRAS); j++) {
/* See the comment in the earlier code; extras are sorted by size. */
if (a_extras[j].len > len - i || !memcmp(a_extras[j].data, out_buf + i, a_extras[j].len) || !memchr(eff_map + EFF_APOS(i), 1, EFF_SPAN_ALEN(i, a_extras[j].len))) {
stage_max--; continue;
}
last_len = a_extras[j].len; memcpy(out_buf + i, a_extras[j].data, last_len);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
}
/* Restore all the clobbered memory. */ memcpy(out_buf + i, in_buf + i, last_len);
/* The havoc stage mutation code is also invoked when splicing files; if the splice_cycle variable is set, generate different descriptions and such. */
/* First of all, if we've modified in_buf for havoc, let's clean that up... */
if (in_buf != orig_in) { ck_free(in_buf); in_buf = orig_in; len = queue_cur->len; } // 首先为了havoc清理in_buf
/* Pick a random queue entry and seek to it. Don't splice with yourself. */
do { tid = UR(queued_paths); } while (tid == current_entry); // 选择一个随机queue内实例 splicing_with = tid; target = queue;
while (tid >= 100) { target = target->next_100; tid -= 100; } while (tid--) target = target->next; /* Make sure that the target has a reasonable length. */
while (target && (target->len < 2 || target == queue_cur)) { target = target->next; splicing_with++; } // 对长度的检查 if (!target) goto retry_splicing; // 如果直到遍历到最后都没有找到适合长度的,就重试 /* Read the testcase into a new buffer. */
fd = open(target->fname, O_RDONLY); if (fd < 0) PFATAL("Unable to open '%s'", target->fname);
new_buf = ck_alloc_nozero(target->len);
ck_read(fd, new_buf, target->len, target->fname);
close(fd);
/* Find a suitable splicing location, somewhere between the first and the last differing byte. Bail out if the difference is just a single byte or so. */
/* Although the trimmer will be less useful when variable behavior is detected, it will still work to some extent, so we don't check for this. */
if (q->len < 5) return0;
stage_name = tmp; bytes_trim_in += q->len;
/* Select initial chunk len, starting with large steps. */
len_p2 = next_p2(q->len); // 以2的幂次向上取整 remove_len = MAX(len_p2 / TRIM_START_STEPS, TRIM_MIN_BYTES); /* Continue until the number of steps gets too high or the stepover gets too small. */
while (remove_len >= MAX(len_p2 / TRIM_END_STEPS, TRIM_MIN_BYTES)) {
if (stop_soon || fault == FAULT_ERROR) goto abort_trimming;
/* Note that we don't keep track of crashes or hangs here; maybe TODO? */
cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST); /* If the deletion had no impact on the trace, make it permanent. This isn't perfect for variable-path inputs, but we're just making a best-effort pass, so it's not a big deal if we end up with false negatives every now and then. */
memmove(in_buf + remove_pos, in_buf + remove_pos + trim_avail, move_tail); // 如果是,则更新testcase的len以及内存中的testcase /* Let's save a clean trace, which will be needed by update_bitmap_score once we're done with the trimming stuff. */
/* Adjust score based on execution speed of this path, compared to the global average. Multiplier ranges from 0.1x to 3x. Fast inputs are less expensive to fuzz, so we're giving them more air time. */
/* Adjust score based on handicap. Handicap is proportional to how late in the game we learned about this path. Latecomers are allowed to run for a bit longer until they catch up with the rest. */
/* Final adjustment based on input depth, under the assumption that fuzzing deeper test cases is more likely to reveal stuff that can't be discovered with traditional fuzzers. */