IORING_SETUP_SQPOLL
When this flag is specified, a kernel thread is created to
perform submission queue polling. An io_uring instance
configured in this way enables an application to issue I/O
without ever context switching into the kernel. By using
the submission queue to fill in new submission queue
entries and watching for completions on the completion
queue, the application can submit and reap I/Os without
doing a single system call.
If the kernel thread is idle for more than sq_thread_idle
milliseconds, it will set the IORING_SQ_NEED_WAKEUP bit in
the flags field of the struct io_sq_ring. When this
happens, the application must call io_uring_enter(2) to
wake the kernel thread. If I/O is kept busy, the kernel
thread will never sleep. An application making use of
this feature will need to guard the io_uring_enter(2) call
with the following code sequence:
/*
* Ensure that the wakeup flag is read after the tail pointer
* has been written. It’s important to use memory load acquire
* semantics for the flags read, as otherwise the application
* and the kernel might not agree on the consistency of the
* wakeup flag.
*/
unsigned flags = atomic_load_relaxed(sq_ring->flags);
if (flags & IORING_SQ_NEED_WAKEUP)
io_uring_enter(fd, 0, 0, IORING_ENTER_SQ_WAKEUP);
IORING_SETUP_IOPOLL
Perform busy-waiting for an I/O completion, as opposed to
getting notifications via an asynchronous IRQ (Interrupt
Request). The file system (if any) and block device must
support polling in order for this to work. Busy-waiting
provides lower latency, but may consume more CPU resources
than interrupt driven I/O. Currently, this feature is
usable only on a file descriptor opened using the O_DIRECT
flag. When a read or write is submitted to a polled
context, the application must poll for completions on the
CQ ring by calling io_uring_enter(2). It is illegal to
mix and match polled and non-polled I/O on an io_uring
instance.
This is only applicable for storage devices for now, and
the storage device must be configured for polling. How to
do that depends on the device type in question. For NVMe
devices, the nvme driver must be loaded with the
poll_queues parameter set to the desired number of polling
queues. The polling queues will be shared appropriately
between the CPUs in the system, if the number is less than
the number of online CPU threads.
structio_uring_sqe { __u8 opcode; /* type of operation for this sqe */ __u8 flags; /* IOSQE_ flags */ __u16 ioprio; /* ioprio for the request */ __s32 fd; /* file descriptor to do IO on */ union { __u64 off; /* offset into file */ __u64 addr2; struct { __u32 cmd_op; __u32 __pad1; }; }; union { __u64 addr; /* pointer to buffer or iovecs */ __u64 splice_off_in; }; __u32 len; /* buffer size or number of iovecs */ union { __kernel_rwf_t rw_flags; __u32 fsync_flags; __u16 poll_events; /* compatibility */ __u32 poll32_events; /* word-reversed for BE */ __u32 sync_range_flags; __u32 msg_flags; __u32 timeout_flags; __u32 accept_flags; __u32 cancel_flags; __u32 open_flags; __u32 statx_flags; __u32 fadvise_advice; __u32 splice_flags; __u32 rename_flags; __u32 unlink_flags; __u32 hardlink_flags; __u32 xattr_flags; __u32 msg_ring_flags; __u32 uring_cmd_flags; }; __u64 user_data; /* data to be passed back at completion time */ /* pack this to avoid bogus arm OABI complaints */ union { /* index into fixed buffers, if used */ __u16 buf_index; /* for grouped buffer selection */ __u16 buf_group; } __attribute__((packed)); /* personality to use, if used */ __u16 personality; union { __s32 splice_fd_in; __u32 file_index; struct { __u16 addr_len; __u16 __pad3[1]; }; }; union { struct { __u64 addr3; __u64 __pad2[1]; }; /* * If the ring is initialized with IORING_SETUP_SQE128, then * this field is used for 80 bytes of arbitrary command data */ __u8 cmd[0]; }; };
structio_uring_sqe { __u8 opcode; // 任务的类型, 用一系列枚举变量来表示 __u8 flags; // 任务的一些标志位, 可以设置任务的一些特性 __u16 ioprio; /* ioprio for the request */ __s32 fd; /* file descriptor to do IO on */ union { __u64 off; /* offset into file */ __u64 addr2; struct { __u32 cmd_op; __u32 __pad1; }; }; union { __u64 addr; /* pointer to buffer or iovecs */ __u64 splice_off_in; }; __u32 len; /* buffer size or number of iovecs */ union { __kernel_rwf_t rw_flags; __u32 fsync_flags; __u16 poll_events; /* compatibility */ __u32 poll32_events; /* word-reversed for BE */ __u32 sync_range_flags; __u32 msg_flags; __u32 timeout_flags; __u32 accept_flags; __u32 cancel_flags; __u32 open_flags; __u32 statx_flags; __u32 fadvise_advice; __u32 splice_flags; __u32 rename_flags; __u32 unlink_flags; __u32 hardlink_flags; __u32 xattr_flags; __u32 msg_ring_flags; __u32 uring_cmd_flags; }; __u64 user_data; /* data to be passed back at completion time */ /* pack this to avoid bogus arm OABI complaints */ union { /* index into fixed buffers, if used */ __u16 buf_index; /* for grouped buffer selection */ __u16 buf_group; } __attribute__((packed)); /* personality to use, if used */ __u16 personality; union { __s32 splice_fd_in; __u32 file_index; struct { __u16 addr_len; __u16 __pad3[1]; }; }; union { struct { __u64 addr3; __u64 __pad2[1]; }; /* * If the ring is initialized with IORING_SETUP_SQE128, then * this field is used for 80 bytes of arbitrary command data */ __u8 cmd[0]; }; };
/* submission data */ struct { structmutexuring_lock;
/* * Ring buffer of indices into array of io_uring_sqe, which is * mmapped by the application using the IORING_OFF_SQES offset. * * This indirection could e.g. be used to assign fixed * io_uring_sqe entries to operations and only submit them to * the queue when needed. * * The kernel modifies neither the indices array nor the entries * array. */ u32 *sq_array; structio_uring_sqe *sq_sqes; unsigned cached_sq_head; unsigned sq_entries;
/* * Fixed resources fast path, should be accessed only under * uring_lock, and updated through io_uring_register(2) */ structio_rsrc_node *rsrc_node; atomic_t cancel_seq; structio_file_tablefile_table; unsigned nr_user_files; unsigned nr_user_bufs; structio_mapped_ubuf **user_bufs;
/* * ->iopoll_list is protected by the ctx->uring_lock for * io_uring instances that don't use IORING_SETUP_SQPOLL. * For SQPOLL, only the single threaded io_sq_thread() will * manipulate the list, hence no extra locking is needed there. */ structio_wq_work_listiopoll_list; bool poll_multi_queue; } ____cacheline_aligned_in_smp;
struct { /* * We cache a range of free CQEs we can use, once exhausted it * should go through a slower range setup, see __io_get_cqe() */ structio_uring_cqe *cqe_cached; structio_uring_cqe *cqe_sentinel;
/* * If IORING_SETUP_NO_MMAP is used, then the below holds * the gup'ed pages for the two rings, and the sqes. */ unsignedshort n_ring_pages; unsignedshort n_sqe_pages; structpage **ring_pages; structpage **sqe_pages; };
int __io_uring_queue_init_params(unsigned entries, struct io_uring *ring, struct io_uring_params *p, void *buf, size_t buf_size) { int fd, ret = 0; unsigned *sq_array; unsigned sq_entries, index;
memset(ring, 0, sizeof(*ring));
/* * The kernel does this check already, but checking it here allows us * to avoid handling it below. */ if (p->flags & IORING_SETUP_REGISTERED_FD_ONLY && !(p->flags & IORING_SETUP_NO_MMAP)) return -EINVAL; // 如果设置了REGISTERED_FD_ONLY 就必须要设置 NO_MMAP
staticlongio_uring_setup(u32 entries, struct io_uring_params __user *params) { structio_uring_paramsp; int i;
if (copy_from_user(&p, params, sizeof(p))) return -EFAULT; // 将params复制到内核空间 for (i = 0; i < ARRAY_SIZE(p.resv); i++) { if (p.resv[i]) return -EINVAL; }
p->sq_entries = roundup_pow_of_two(entries); if (p->flags & IORING_SETUP_CQSIZE) { /* * If IORING_SETUP_CQSIZE is set, we do the same roundup * to a power-of-two, if it isn't already. We do NOT impose * any cq vs sq ring sizing. */ if (!p->cq_entries) return -EINVAL; if (p->cq_entries > IORING_MAX_CQ_ENTRIES) { if (!(p->flags & IORING_SETUP_CLAMP)) return -EINVAL; p->cq_entries = IORING_MAX_CQ_ENTRIES; } p->cq_entries = roundup_pow_of_two(p->cq_entries); if (p->cq_entries < p->sq_entries) return -EINVAL; } else { p->cq_entries = 2 * p->sq_entries; }
if (ctx->task_complete || (ctx->flags & IORING_SETUP_IOPOLL)) ctx->lockless_cq = true;
/* * lazy poll_wq activation relies on ->task_complete for synchronisation * purposes, see io_activate_pollwq() */ if (!ctx->task_complete) ctx->poll_activated = true;
/* * When SETUP_IOPOLL and SETUP_SQPOLL are both enabled, user * space applications don't need to do io completion events * polling again, they can rely on io_sq_thread to do polling * work, which can reduce cpu usage and uring_lock contention. */ if (ctx->flags & IORING_SETUP_IOPOLL && !(ctx->flags & IORING_SETUP_SQPOLL)) ctx->syscall_iopoll = 1;
ctx->compat = in_compat_syscall(); if (!ns_capable_noaudit(&init_user_ns, CAP_IPC_LOCK)) ctx->user = get_uid(current_user());
/* * For SQPOLL, we just need a wakeup, always. For !SQPOLL, if * COOP_TASKRUN is set, then IPIs are never needed by the app. */ ret = -EINVAL; if (ctx->flags & IORING_SETUP_SQPOLL) { /* IPI related flags don't make sense with SQPOLL */ if (ctx->flags & (IORING_SETUP_COOP_TASKRUN | IORING_SETUP_TASKRUN_FLAG | IORING_SETUP_DEFER_TASKRUN)) goto err; ctx->notify_method = TWA_SIGNAL_NO_IPI; } elseif (ctx->flags & IORING_SETUP_COOP_TASKRUN) { ctx->notify_method = TWA_SIGNAL_NO_IPI; } else { if (ctx->flags & IORING_SETUP_TASKRUN_FLAG && !(ctx->flags & IORING_SETUP_DEFER_TASKRUN)) goto err; ctx->notify_method = TWA_SIGNAL; }
/* * For DEFER_TASKRUN we require the completion task to be the same as the * submission task. This implies that there is only one submitter, so enforce * that. */ if (ctx->flags & IORING_SETUP_DEFER_TASKRUN && !(ctx->flags & IORING_SETUP_SINGLE_ISSUER)) { goto err; }
/* * This is just grabbed for accounting purposes. When a process exits, * the mm is exited and dropped before the files, hence we need to hang * on to this mm purely for the purposes of being able to unaccount * memory (locked/pinned vm). It's not used for anything else. */ mmgrab(current->mm); ctx->mm_account = current->mm;
[[#io_allocate_scq_urings ]] 分配了scq和rings的内存
[[#io_sq_offload_create]] 创建了任务处理线程
1 2 3 4 5 6 7 8 9 10 11
ret = io_allocate_scq_urings(ctx, p); if (ret) goto err;
ret = io_sq_offload_create(ctx, p); if (ret) goto err;
if (ctx->flags & IORING_SETUP_SINGLE_ISSUER && !(ctx->flags & IORING_SETUP_R_DISABLED)) WRITE_ONCE(ctx->submitter_task, get_task_struct(current));
file = io_uring_get_file(ctx); if (IS_ERR(file)) { ret = PTR_ERR(file); goto err; }
ret = __io_uring_add_tctx_node(ctx); if (ret) goto err_fput; tctx = current->io_uring;
/* * Install ring fd as the very last thing, so we don't risk someone * having closed it before we finish setup */ if (p->flags & IORING_SETUP_REGISTERED_FD_ONLY) ret = io_ring_add_registered_file(tctx, file, 0, IO_RINGFD_REG_MAX); else ret = io_uring_install_fd(file); if (ret < 0) goto err_fput;
/* * Ring fd has been registered via IORING_REGISTER_RING_FDS, we * need only dereference our task private array to find it. */ if (flags & IORING_ENTER_REGISTERED_RING) { structio_uring_task *tctx = current->io_uring;
if (unlikely(!tctx || fd >= IO_RINGFD_REG_MAX)) return -EINVAL; fd = array_index_nospec(fd, IO_RINGFD_REG_MAX); f.file = tctx->registered_rings[fd]; f.flags = 0; if (unlikely(!f.file)) return -EBADF; } else { f = fdget(fd); if (unlikely(!f.file)) return -EBADF; ret = -EOPNOTSUPP; if (unlikely(!io_is_uring_fops(f.file))) goto out; }
ctx = f.file->private_data; ret = -EBADFD; if (unlikely(ctx->flags & IORING_SETUP_R_DISABLED)) goto out;
/* * For SQ polling, the thread will do all submissions and completions. * Just return the requested submit count, and wake the thread if * we were asked to. */ ret = 0; if (ctx->flags & IORING_SETUP_SQPOLL) { io_cqring_overflow_flush(ctx);
if (unlikely(ctx->sq_data->thread == NULL)) { ret = -EOWNERDEAD; goto out; } if (flags & IORING_ENTER_SQ_WAKEUP) // 这个flag处于和用户态共享的内存 // 如果sq处理线程休眠了,并需要唤醒 // 可以通过设置 IORING_ENTER_SQ_WAKEUP, 再通过此syscall 来唤醒 wake_up(&ctx->sq_data->wait); if (flags & IORING_ENTER_SQ_WAIT) io_sqpoll_wait_sq(ctx);
if (flags & IORING_ENTER_GETEVENTS) { // 如果请求获取完成事件 int ret2;
if (ctx->syscall_iopoll) { // 如果开启了syscall轮询模式,执行iopoll逻辑 /* * We disallow the app entering submit/complete with * polling, but we still need to lock the ring to * prevent racing with polled issue that got punted to * a workqueue. */ mutex_lock(&ctx->uring_lock); iopoll_locked: ret2 = io_validate_ext_arg(flags, argp, argsz); if (likely(!ret2)) { min_complete = min(min_complete, ctx->cq_entries); ret2 = io_iopoll_check(ctx, min_complete); } mutex_unlock(&ctx->uring_lock); } else { constsigset_t __user *sig; struct __kernel_timespec __user *ts;
/* * EBADR indicates that one or more CQE were dropped. * Once the user has been informed we can clear the bit * as they are obviously ok with those drops. */ if (unlikely(ret2 == -EBADR)) clear_bit(IO_CHECK_CQ_DROPPED_BIT, &ctx->check_cq); } }
if (ctx->sq_creds != current_cred()) creds = override_creds(ctx->sq_creds); // 保存和恢复 creds 身份信息避免安全漏洞 mutex_lock(&ctx->uring_lock); // 上锁保护关键区 if (!wq_list_empty(&ctx->iopoll_list)) io_do_iopoll(ctx, true); // 处理 iopoll 轮询事件 /* * Don't submit if refs are dying, good for io_uring_register(), * but also it is relied upon by io_ring_exit_work() */ if (to_submit && likely(!percpu_ref_is_dying(&ctx->refs)) && !(ctx->flags & IORING_SETUP_R_DISABLED)) ret = io_submit_sqes(ctx, to_submit); // 提交请求到 SQ 环 mutex_unlock(&ctx->uring_lock);
if (to_submit && wq_has_sleeper(&ctx->sqo_sq_wait)) wake_up(&ctx->sqo_sq_wait); // 唤醒 sqo_sq 等待线程 if (creds) revert_creds(creds); }
if (unlikely(!entries)) return0; /* make sure SQ entry isn't read before tail */ ret = left = min(nr, entries); io_get_task_refs(left); io_submit_state_start(&ctx->submit_state, left);
循环处理每个sqes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
do { conststructio_uring_sqe *sqe; structio_kiocb *req;
if (unlikely(!io_alloc_req(ctx, &req))) break; if (unlikely(!io_get_sqe(ctx, &sqe))) { io_req_add_to_cache(req, ctx); break; } // 为每个SQE分配并初始化io_kiocb请求 if (unlikely(io_submit_sqe(ctx, req, sqe)) && // 真正的提交 !(ctx->flags & IORING_SETUP_SUBMIT_ALL)) { left--; break; } } while (--left);
ret = io_init_req(ctx, req, sqe); // 初始化并校验SQE请求req if (unlikely(ret)) return io_submit_fail_init(sqe, req, ret); // 如果已有链头或者SQE标记了链接标志
trace_io_uring_submit_req(req);
/* * If we already have a head request, queue this one for async * submittal once the head completes. If we don't have a head but * IOSQE_IO_LINK is set in the sqe, start a new head. This one will be * submitted sync once the chain is complete. If none of those * conditions are true (normal request), then just queue it. */ if (unlikely(link->head)) { // 如果链表已经有了一个head 请求, 意味着之前sqe 有 `IOSQE_IO_LINK` 标志 ret = io_req_prep_async(req); // 准备异步提交状态 if (unlikely(ret)) return io_submit_fail_init(sqe, req, ret); trace_io_uring_link(req, link->head); link->last->link = req; link->last = req; // 将本项挂载到链表 if (req->flags & IO_REQ_LINK_FLAGS) return0; // 如果此项没有 LINK 标志, 清空 链表 /* last request of the link, flush it */ req = link->head; link->head = NULL;
if (req->flags & (REQ_F_FORCE_ASYNC | REQ_F_FAIL)) goto fallback;
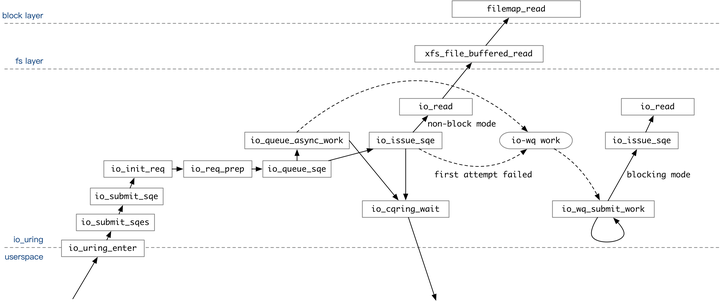
staticinlinevoidio_queue_sqe(struct io_kiocb *req) __must_hold(&req->ctx->uring_lock) { int ret;
ret = io_issue_sqe(req, IO_URING_F_NONBLOCK|IO_URING_F_COMPLETE_DEFER);
/* * We async punt it if the file wasn't marked NOWAIT, or if the file * doesn't support non-blocking read/write attempts */ if (likely(!ret)) io_arm_ltimeout(req); else io_queue_async(req, ret); }
if (unlikely(!io_assign_file(req, def, issue_flags))) return -EBADF; // 为请求分配文件描述符 if (unlikely((req->flags & REQ_F_CREDS) && req->creds != current_cred())) creds = override_creds(req->creds); // 备份和恢复请求执行线程的安全凭证 if (!def->audit_skip) audit_uring_entry(req->opcode); // 调用audit跟踪提交事件
ret = def->issue(req, issue_flags); // 调用def->issue执行请求
if (!def->audit_skip) audit_uring_exit(!ret, ret);
if (creds) revert_creds(creds); // 恢复凭证 if (ret == IOU_OK) { if (issue_flags & IO_URING_F_COMPLETE_DEFER) // 如果成功并且标记了延迟完成,注册延迟完成回调 io_req_complete_defer(req); else io_req_complete_post(req, issue_flags); // 否则直接提交完成 } elseif (ret != IOU_ISSUE_SKIP_COMPLETE) return ret;
/* If the op doesn't have a file, we're not polling for it */ if ((req->ctx->flags & IORING_SETUP_IOPOLL) && def->iopoll_queue) io_iopoll_req_issued(req, issue_flags);
staticinlinevoidio_queue_sqe(struct io_kiocb *req) __must_hold(&req->ctx->uring_lock) { int ret;
ret = io_issue_sqe(req, IO_URING_F_NONBLOCK|IO_URING_F_COMPLETE_DEFER);
/* * We async punt it if the file wasn't marked NOWAIT, or if the file * doesn't support non-blocking read/write attempts */ if (likely(!ret)) io_arm_ltimeout(req); else io_queue_async(req, ret); }
/* init ->work of the whole link before punting */ io_prep_async_link(req); // 为链少的每一个 req 准备work结构 /* * Not expected to happen, but if we do have a bug where this _can_ * happen, catch it here and ensure the request is marked as * canceled. That will make io-wq go through the usual work cancel * procedure rather than attempt to run this request (or create a new * worker for it). */ if (WARN_ON_ONCE(!same_thread_group(req->task, current))) req->work.flags |= IO_WQ_WORK_CANCEL;
trace_io_uring_queue_async_work(req, io_wq_is_hashed(&req->work)); io_wq_enqueue(tctx->io_wq, &req->work); if (link) io_queue_linked_timeout(link); }
/* * If io-wq is exiting for this task, or if the request has explicitly * been marked as one that should not get executed, cancel it here. */ if (test_bit(IO_WQ_BIT_EXIT, &wq->state) || (work->flags & IO_WQ_WORK_CANCEL)) { io_run_cancel(work, wq); return; } // 如果需要取消 work raw_spin_lock(&acct->lock); io_wq_insert_work(wq, work); clear_bit(IO_ACCT_STALLED_BIT, &acct->flags); raw_spin_unlock(&acct->lock);
staticboolio_wq_create_worker(struct io_wq *wq, struct io_wq_acct *acct) { if (unlikely(!acct->max_workers)) pr_warn_once("io-wq is not configured for unbound workers");
/* * If we got some work, mark us as busy. If we didn't, but * the list isn't empty, it means we stalled on hashed work. * Mark us stalled so we don't keep looking for work when we * can't make progress, any work completion or insertion will * clear the stalled flag. */ work = io_get_next_work(acct, worker); raw_spin_unlock(&acct->lock); if (work) { __io_worker_busy(wq, worker);
/* * Make sure cancelation can find this, even before * it becomes the active work. That avoids a window * where the work has been removed from our general * work list, but isn't yet discoverable as the * current work item for this worker. */ raw_spin_lock(&worker->lock); worker->next_work = work; raw_spin_unlock(&worker->lock); } else { break; } io_assign_current_work(worker, work); __set_current_state(TASK_RUNNING);
/* one will be dropped by ->io_wq_free_work() after returning to io-wq */ if (!(req->flags & REQ_F_REFCOUNT)) __io_req_set_refcount(req, 2); else req_ref_get(req);
io_arm_ltimeout(req);
/* either cancelled or io-wq is dying, so don't touch tctx->iowq */ if (work->flags & IO_WQ_WORK_CANCEL) { fail: io_req_task_queue_fail(req, err); return; } if (!io_assign_file(req, def, issue_flags)) { err = -EBADF; work->flags |= IO_WQ_WORK_CANCEL; goto fail; }
do { ret = io_issue_sqe(req, issue_flags); // 最终还是调用了 io_issue_sqe 来处理任务 if (ret != -EAGAIN) break;
/* * If REQ_F_NOWAIT is set, then don't wait or retry with * poll. -EAGAIN is final for that case. */ if (req->flags & REQ_F_NOWAIT) break;
/* * We can get EAGAIN for iopolled IO even though we're * forcing a sync submission from here, since we can't * wait for request slots on the block side. */ if (!needs_poll) { if (!(req->ctx->flags & IORING_SETUP_IOPOLL)) break; if (io_wq_worker_stopped()) break; cond_resched(); continue; }
if (io_arm_poll_handler(req, issue_flags) == IO_APOLL_OK) return; /* aborted or ready, in either case retry blocking */ needs_poll = false; issue_flags &= ~IO_URING_F_NONBLOCK; } while (1);
/* avoid locking problems by failing it from a clean context */ if (ret < 0) io_req_task_queue_fail(req, ret); }